 dini
dini안녕하세요! 쏘카 데이터 엔지니어링 팀의 디니입니다.
저는 2021년 8월에 쏘카 데이터 엔지니어링 팀에 신입 데이터 엔지니어로 입사했습니다. 지난 4개월간 데이터 엔지니어링 팀에서 경험하며 느낀 점을 공유하려 합니다. 그 중 데이터 엔지니어링 팀의 온보딩과 실무를 겪으며 느낀 내용을 주로 다루었습니다. 혹시 데이터 분석가나 데이터 사이언티스트의 내용이 궁금하신 분은 쏘카 데이터 그룹 - 데이터 사이언티스트 인턴 9개월 후기를 보시면 도움이 될 것 같습니다.
다음과 같은 분들이 읽으시면 도움이 될 것 같습니다.
- 쏘카 데이터 엔지니어링 팀의 신입 채용 과정이 궁금하신 분
- 쏘카 데이터 엔지니어링 팀에 입사한 인원이 빠르게 회사에 적응하기 위한 온보딩 과정이 궁금하신 분
- 온보딩 프로세스를 만들려고 하시는 분
- 쏘카 데이터 엔지니어링 팀이 어떻게 일을 하는지 관심 있으신 분
목차
목차는 다음과 같습니다. 각 제목을 클릭하시면 해당 부분으로 이동하실 수 있습니다.
- 입사 지원 배경과 과정
- 지원 배경
- 입사 과정
- 입사 후 온보딩 과정
- 온보딩 과제
- 과제 후 얻은 것
- 마무리 발표
- 그 외 온보딩 & 밍글링 과정
- 온보딩 후 실무 투입 과정
- 첫 프로젝트 : 메타데이터 플랫폼 구축
- 각종 파티 참여
- 온보딩 과정이 어떻게 도움되었나요?
- 앞으로는 무엇을?
- Q & A
1. 입사 지원 배경과 과정
먼저 제가 회사를 지원하게 된 배경과 그 과정을 말씀드립니다.
지원 배경
저는 대학에서 경영학을 전공했고, 처음에는 데이터 분석에 관심이 있었습니다. 그런데 우연한 계기로 실시간 API의 데이터를 가공하여 데이터베이스에 적재하고 지표를 만드는 경험을 한 뒤, 데이터 엔지니어링의 매력을 느끼게 되었습니다.
데이터 분석과 실험을 잘 하려면 원천(Raw) 데이터와 데이터 인프라 환경이 잘 만들어져야 하고, 이런 환경을 구축하는 것이 데이터 엔지니어링이라고 생각했습니다. 인프라, Database, 개발 등 다양한 경험을 할 수 있는 데이터 엔지니어가 멋있어(!) 보였고, 그렇게 저는 쏘카 데이터 엔지니어 포지션에 지원하게 되었습니다.
입사 과정
쏘카 데이터 엔지니어링의 채용 프로세스는 다음처럼 진행되었습니다.
- 서류 제출
- 전화 면접
- 1차 면접(기술 면접)
- 2차 면접(임원 면접)
- 처우 협의
- 최종 합격
1. 서류 제출
원티드를 통해 서류를 제출했습니다. 따로 자기소개서 양식은 없었고, 과거 프로젝트 경험이 담긴 이력서와 함께 개인 블로그와 Github를 첨부했습니다.
2. 전화 면접
이력서에 있는 경험들과 데이터 엔지니어링에 대해 얼마나 알고 있는지를 중심으로 면접이 진행되었습니다. 업무 관련 문제 해결 경험, 관련 프레임워크를 써보거나 공부한 경험, DB 관련 개념은 알고 있는지 등의 질문이 있었습니다. 데이터 엔지니어링 팀장이신 토마스가 면접을 해주셨고 30분 정도 진행되었습니다.
3. 1차 면접 (기술 면접)
1차 기술 면접엔 포트폴리오 위주로 직무 관련 꼬리 질문이 이어졌습니다. 그 뒤에 코딩테스트가 있었는데, 총 3문제를 한 시간에 걸쳐 풀었습니다. 면접자에게 시간을 주고 풀게 한 뒤, 코드를 보면서 질문과 답변을 주고받는 형식이었습니다. 멀티 스레드, 클래스 등의 개념과 파이썬을 통한 로직 구현, SQL 쿼리의 여러 기능과 활용법을 알아야 하는 질문이 나왔습니다.
이론적인 알고리즘 문제보다 현업에서 마주칠만한 문제 상황을 어떻게 코드로 해결할지를 묻는 질문이었습니다. 쏘카가 모빌리티 기업인 만큼, 모빌리티 관련 도메인 지식도 있으면 좋다 생각했습니다. 정답 여부가 아닌 전체적으로 문제에 접근하는 논리를 보시는 것 같았습니다. 개인적으로 모든 채용 과정 중 가장 긴장을 많이 한 과정이었습니다. 1시간 30분 정도 진행되었습니다.
4. 2차 면접 (임원 면접)
데이터 그룹의 그룹장이신 DK가 면접을 진행했습니다. 대부분 이력서 기반의 인성 질문들이었으나 기술 질문도 있었습니다. 회사에 대해 질문하는 Reverse Interview 과정도 20분 정도 있었습니다. 기술 면접에서 너무 긴장했던 탓인지 2차 면접은 상대적으로 순한맛(?)으로 느껴졌습니다. 1시간 정도 진행되었습니다.
모든 과정의 결과 발표는 1주일 이내로 신속하게 진행되었고, 전화와 이메일을 통해 명확한 의사소통이 이루어졌습니다.
2. 입사 후 온보딩 과정
약 한 달 정도의 채용 프로세스 끝에 드디어 쏘카 데이터 엔지니어링 팀에 입사하게 되었습니다.
쏘카 데이터 엔지니어링 팀은 총 8명으로 쏘카 데이터 엔지니어링 팀이 하는 일은 데이터 엔지니어링 팀의 하디가 작성한 데이터 엔지니어링 팀이 하는 일과 쏘카 데이터 엔지니어 채용공고에 잘 설명되어 있습니다.
며칠 뒤, 2주 동안 4개의 온보딩 과제를 진행하게 되었습니다.
온보딩 과제
이 온보딩 과제는 데이터 엔지니어링 팀에 가장 최근에 입사했던 그랩의 아이디어에서 출발했다고 합니다. 간단한 과제들을 통해 팀에서 다루는 도구와 업무 플로우에 익숙해지는 것이 목표였습니다. 과제를 통해 Kubernetes, Docker, Airflow, FastAPI, Git, Helm Chart와 같은 기술을 경험해볼 수 있었습니다. 구체적으로 과제 내용은 다음과 같았습니다.
1) Docker - Docker 다루기
첫 과제는 간단한 Docker 파일을 만들어 실행하고, Docker Compose로 Airflow를 띄워보는 내용이었습니다.
데이터 엔지니어링 팀은 기본적으로 Kubernetes 환경에서 업무가 진행되기 때문에 Docker 부터 익혀야 한다는 생각으로 만들어진 과제입니다. 맨 처음에는 Docker를 설치하고, Ubuntu 컨테이너를 가져와서 실행하고 접속하여 파일을 만들어보는 등의 과정을 진행했습니다. 그다음에는 Ubuntu 이미지를 기반으로 hello world를 CMD를 이용해 출력하는 파일을 만들었습니다.
이 뒤에는 Docker Compose를 이용해 Airflow를 띄우고 Web UI에 접속하는 것까지 진행했습니다. 이 과정에서 Airflow의 기본 구조도 공부할 수 있었습니다.
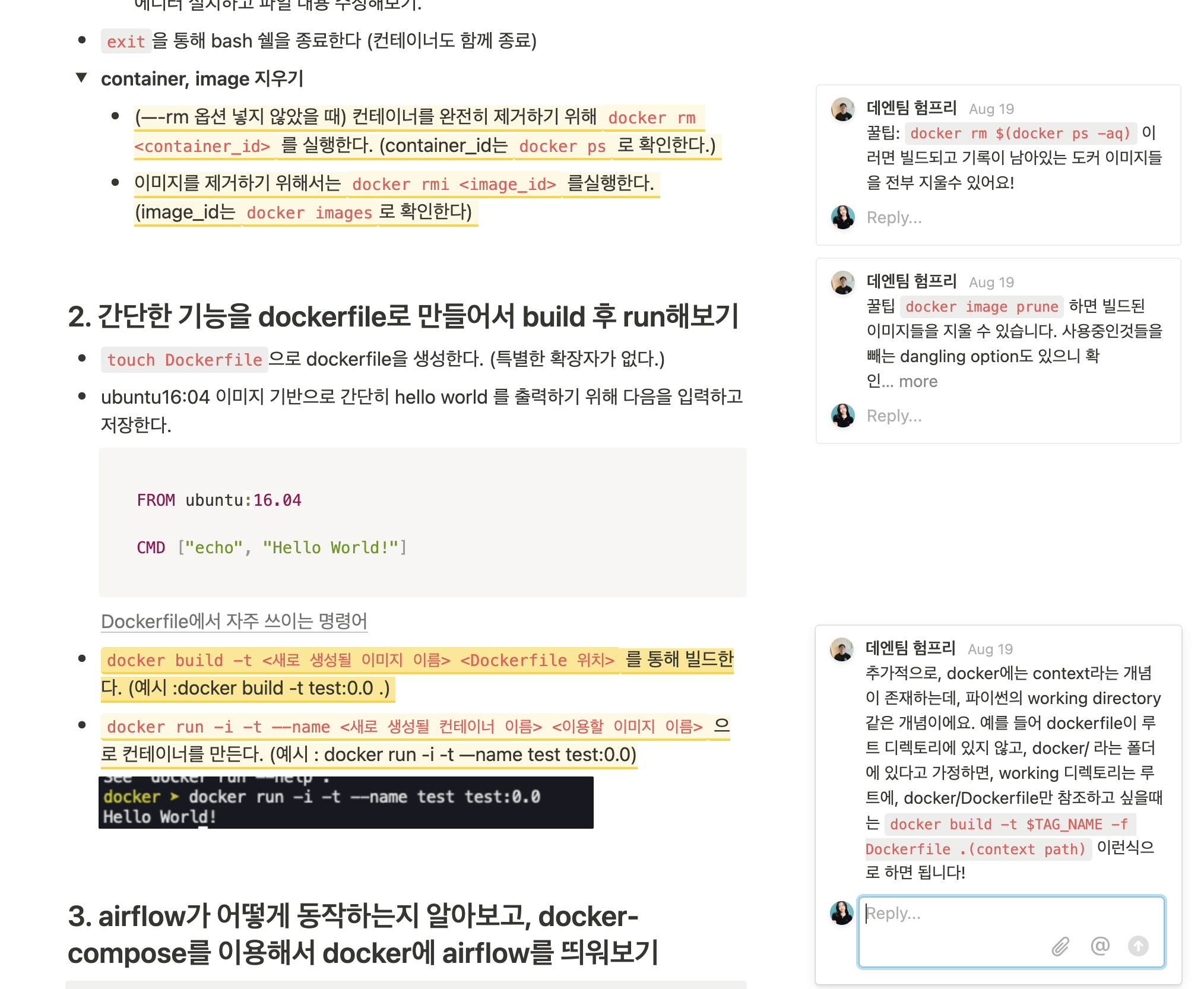 Docker 과제 기록 - 천사 험프리의 코멘트
Docker 과제 기록 - 천사 험프리의 코멘트
2) Docker Compose & Airflow - 간단한 Web Server 개발하기
여기서는 앞에서 배운 Docker Compose를 활용해 웹서버와 DB를 띄우고, 마찬가지로 Docker Compose로 Airflow를 띄운 뒤 웹서버와 통신하는 DAG을 작성하는 과제가 주어졌습니다.
웹 프레임워크는 딱히 제한이 없어, 그나마 익숙했던 Flask로 간단한 웹서버를 만들었습니다. 그다음에 이 웹서버를 띄울 수 있는 Docker 파일을 만들어야 했습니다. 이 과정에서 ENTRYPOINT 와 CMD의 사용법을 익히느라 헤맨 기억이 있습니다.
그리고 DB를 위해 MySQL 컨테이너도 띄우고 (마찬가지로 제일 익숙한 것으로 했습니다.) Docker Compose를 통해 둘을 연결했습니다. 이후 Airflow를 따로 띄운뒤, 만든 웹서버에 HTTP Request를 하는 함수를 PythonOperator로 호출하는 간단한 DAG을 작성했습니다. 여기서 “웹서버에 연결하려면 DAG에서 어떤 주소를 넣어줘야 하는가?”를 트러블슈팅하느라 많이 헤맸는데요. 팀원 험프리의 도움으로 결국 해결할 수 있었습니다.
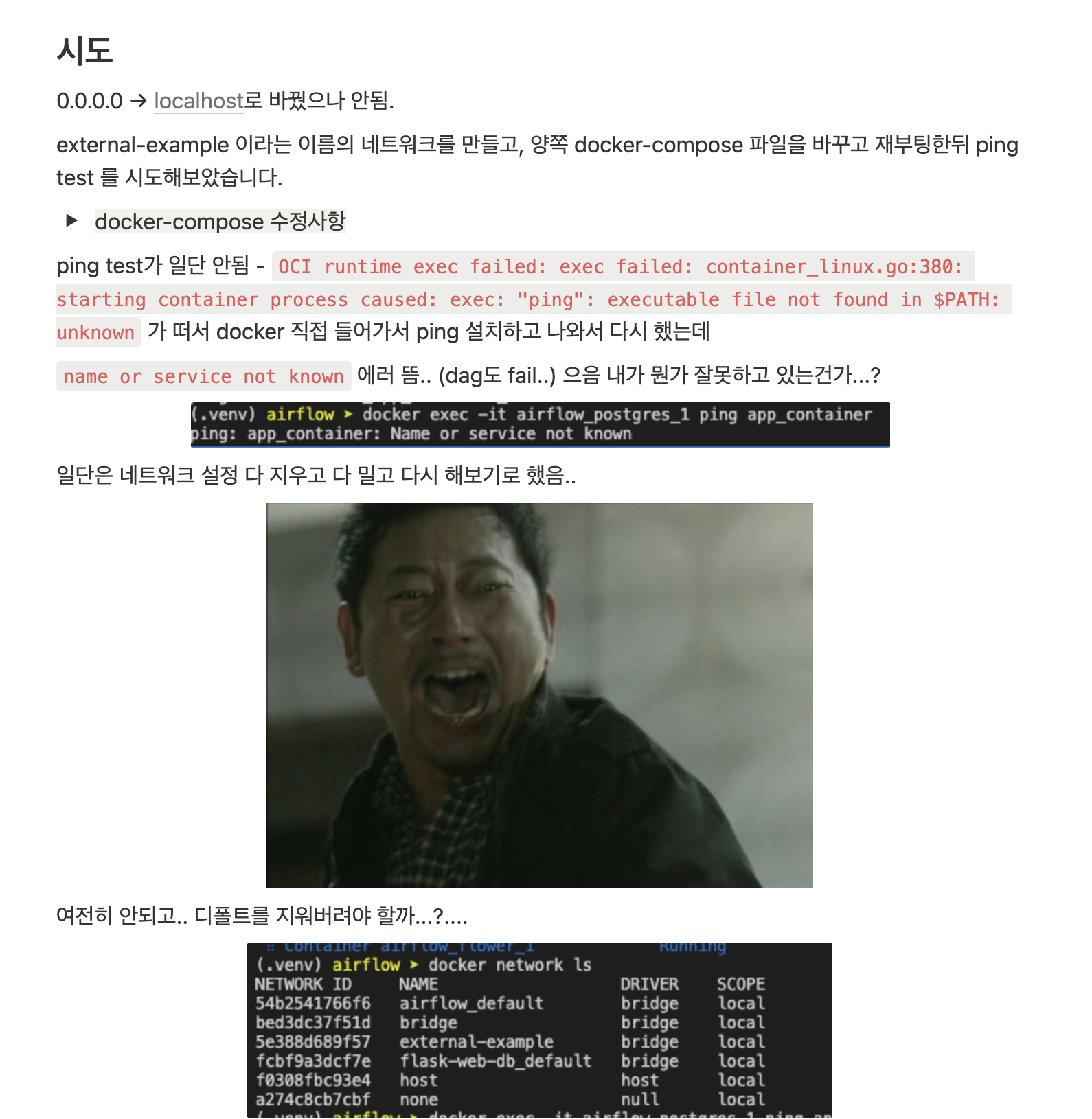 트러블슈팅 기록 - 중간중간 오열했습니다.
트러블슈팅 기록 - 중간중간 오열했습니다.
3) Airflow - 간단한 DAG 만들어서 실행하기
이 과제는 PythonOperator를 이용한 간단한 Airflow DAG을 만들고, 팀의 CI/CD 환경에 배포 및 실행해보는 내용이었습니다. 특정 기능을 구현하는 것보다 팀 업무 환경에 익숙해지기 위한 과제였습니다. 다른 과제보다 수월하게 진행할 수 있었습니다. 또한 저희팀 Git Repository에 다양한 샘플 DAG 코드가 업로드되어 있어서, DAG의 기본 구조 이해에 도움이 되었습니다.
이 과제에서 생성한 DAG 안의 Task의 내용 자체는 매우 단순했지만 (print 문 등), 대신 Task 하나를 실행하거나 여러 Task를 병렬 처리하는 DAG를 생성해봤습니다.
4) Kubernetes - Helm chart를 작성하여 웹서버를 Kubernetes에 배포하기
이 과제는 간단한 API 서버를 구축하고 Docker로 빌드하여 GCR(Google Container Registry)에 이미지로 Push한 뒤, Helm Chart를 작성하여 이 이미지를 GKE(Google Kubernetes Engine)에 배포하는 과정이었습니다. Helm Chart 기능들을 배우면서 팀 환경에도 익숙해지기 위한 과제였습니다.
이 과제에서도 웹 프레임워크는 딱히 정해지지 않았지만, 팀에서 FastAPI를 자주 쓰고 있었기 때문에 겸사겸사해서 FastAPI로 웹서버를 구현했습니다. (이 과정에서 저만의 셀프 FastAPI 온보딩 과제- 간단한 CRUD 서버 구축해보기도 있었습니다.)
Helm Chart를 직접 만들고 values.yaml 을 작성하는 방법, GKE 환경을 설정하는 방법 등 짧은 시간에 많은 걸 접하고 배울 수 있었습니다. 처음에는 Kubernetes의 개념을 익히기 위해 minikube 로 테스트를 해봤고, 나중엔 팀 GKE에서 실습했습니다. 회사 GKE에서만 할 수 있는 설정들(GCR에 있는 이미지 Pull, Ingress 할당 등)이 있어서 조금 헤맸던 기억이 있습니다.
과제 후 얻은 것
이렇게 4개의 온보딩 과제를 완료하는데 총 2주가 걸렸습니다. 신입 입장에서 이렇게 전체적으로 업무의 흐름을 파악하는 시간이 주어진 게 정말 감사한 일이었습니다. 👍
모든 회사에서 이런 기회가 주어지지 않는다는 것을 알기에 더욱 소중한 시간이었습니다.
가장 큰 장점은 “업무 적응에 대한 심적 부담이 크게 줄었다!”입니다. 사실 데이터 엔지니어링 팀에 필요한 도메인이 매우 넓은데, 관련 경험이 거의 없어서 처음에 막연한 두려움이 있었습니다. 그런데 Task 자체는 매우 단순화한 상태에서 프레임워크를 사용해보고 플로우를 익혀보니, 좀 더 복잡한 업무도 “아, 일단 이건 해봤으니까 여기서 발전해나가면 되겠구나!” 하는 자신감이 생겼습니다.
첫 환경 세팅이나 배포의 난관을 온보딩 과제를 통해 극복할 수 있던 것도 큰 의미가 있었습니다. 프레임워크뿐만 아니라 Lens 등 팀에서 활용하고 있는 모니터링 도구도 이때 빨리 접할 수 있었습니다. 팀 문서나 코드도 점점 눈에 들어오기 시작했습니다. 그리고 트러블슈팅 과정을 기록한 것들을 공유하며, 제가 어떤 부분에서 부족한지 팀원들의 피드백을 받아볼 수 있어서 좋았습니다.
마무리 발표
이렇게 2주 동안 과제를 수행한 뒤, 온보딩 과제를 회고하는 발표를 하게 되었습니다. 주로 온보딩 과제와 트러블 슈팅 내용들, 제가 느꼈던 감정들 위주였습니다. 발표 후, 이런 식으로 온보딩 과정을 발전 및 정착시켰으면 좋겠다는 논의도 나왔습니다. 앞으로 더 개선된 온보딩 과정이 기대됩니다.
 트러블슈팅 과정 설명
트러블슈팅 과정 설명
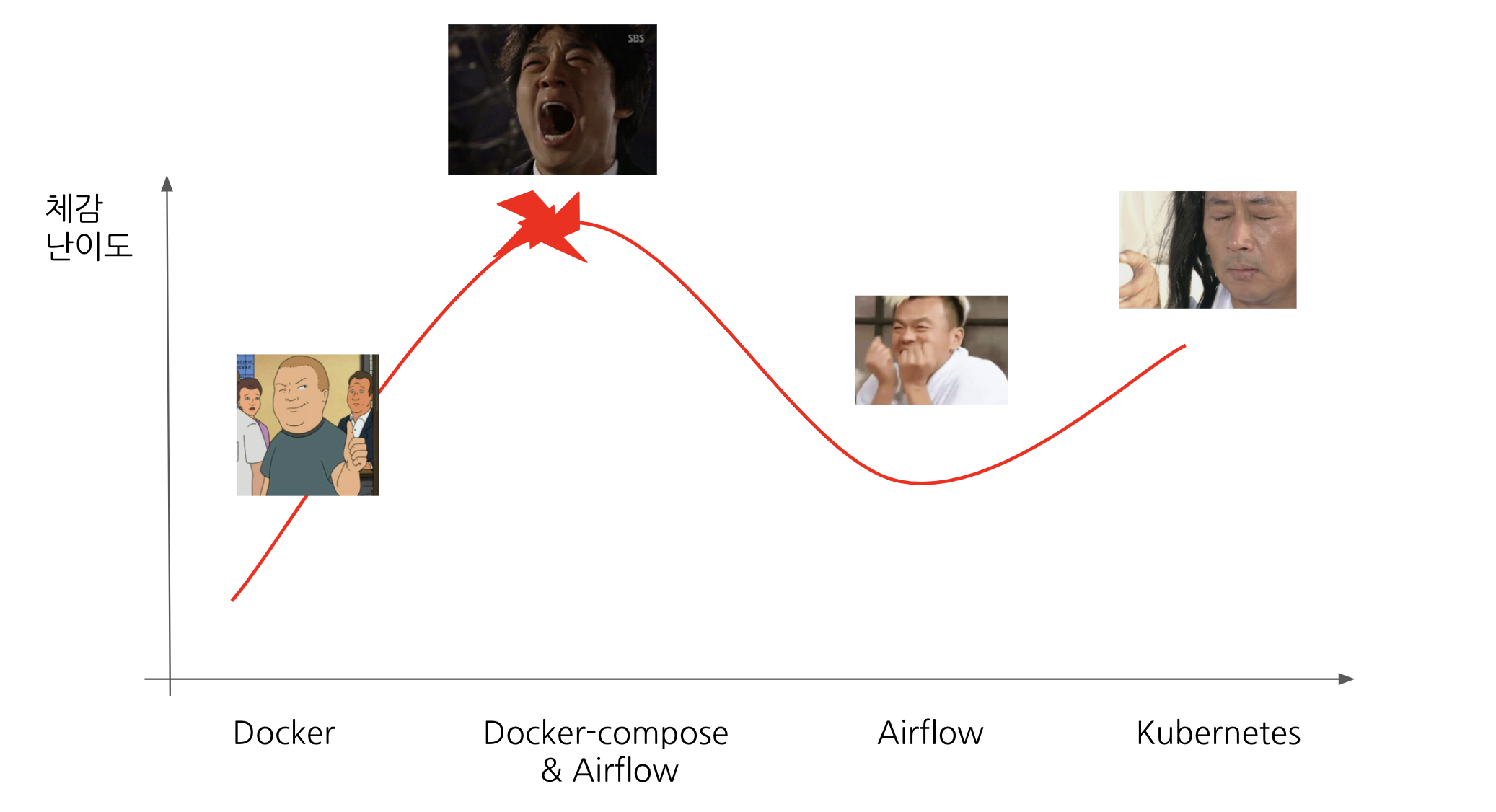 과제에 따른 감정 변화
과제에 따른 감정 변화
그 외 온보딩 & 밍글링 과정
이런 온보딩 과제 외에도 쏘카에서는 다양한 방법으로 적응을 도와주는 아래와 같은 과정이 있습니다. 이런 과정들을 통해 쏘카 데이터 그룹 팀원들과 좀 더 친해지고, 빨리 적응할 수 있었습니다.
1) 각종 온보딩 세션
회사 차원에서 PX(People Experience)팀에서 하루 정도 시간을 잡고 쏘카 회사의 히스토리와 문화에 대해서 알려주는 온보딩 과정이 있었습니다. 또한 PX팀과 따로 1:1 로 티타임을 하고, 온보딩 과정에 대한 만족도 조사를 하는 등 신규 입사자를 세심하게 신경 써주는 느낌을 받았습니다. 데이터 그룹 단위에서는 팀장인 토마스가 3번에 걸쳐 1:1로 한 시간씩 쏘카 데이터 그룹의 인프라와 히스토리를 설명해주는 시간이 있었습니다.
2) 라이브 슬랙
라이브 슬랙은 데이터 그룹엔 신규 입사자가 자기를 소개하는 PPT를 한 장으로 만들어 슬랙(업무용 메신저)에 올리면, 데이터 그룹 전체가 질문하고 신규 입사자는 15분 동안 열심히 답변하는 이벤트입니다. 순발력과 빠른 타자 실력이 요구되었습니다. 참고로 이 문화는 VCNC에서 진행하는 라이브 슬랙을 참고했다고 합니다.
 인상 깊었던 하디의 레전드 질문
인상 깊었던 하디의 레전드 질문
3) 해피아워
데이터 그룹은 한 달에 한 번 금요일 오후에 해피아워를 진행합니다. 해피아워는 다양한 데이터 그룹의 사람들이 서로 친해지며 휴식하는 시간입니다. 코로나가 심하지 않을 때는 영화를 보거나 맥주를 마시러 가기도 했다고 합니다. 코로나 시국에는 비대면으로 마피아게임, 캐치마인드, 몸으로 말해요 등 여러 액티비티를 경험했습니다.
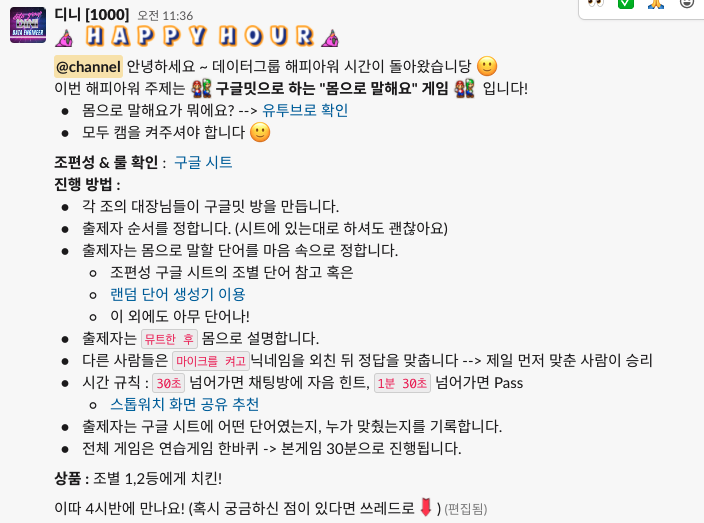 지금은 제가 해피아워 공지를 올립니다.
지금은 제가 해피아워 공지를 올립니다.
3. 실무 투입 과정
이렇게 온보딩 과제를 마무리한 후에도 조금씩 업무에 투입되었습니다. 이 기간에 팀원 그랩이 추천해준 “Kubernetes in Action”이라는 책을 읽으며 정리했습니다.
첫 프로젝트 : 메타데이터 플랫폼 구축
입사 후 처음 맡게 된 프로젝트입니다. 쏘카에선 개발 직군, 비개발 직군 상관없이 많은 분들이 데이터를 적극적으로 이용하고 있습니다. 점점 더 데이터가 복잡해지고 이용자가 늘어나는 상황에서 “어떤 데이터가 어디에 있는지”, “특정 테이블 혹은 칼럼은 어떤 정보를 담고 있는지”, 즉 메타데이터를 쉽게 파악하는 일이 중요해졌습니다.
이런 메타데이터의 효율적 관리를 위한 “전사적 메타데이터 플랫폼”을 도입하는 과정에 카일과 함께 참여하게 되었습니다. 현재는 Datahub라는 프레임워크를 선택하여 GKE에서 테스트 과정 중에 있으며, 추후 전사 플랫폼으로 도입할 예정입니다. 기획 단계부터 리서치, 테스트와 배포와 커스텀 기능 개발까지 경험할 수 있어서 정말 재밌게 하고 있습니다.
구체적으로는 다음과 같은 일들을 해볼 수 있었습니다.
- Data Ingestion 과정을 Docker 이미지로 만들고 Airflow DAG에 연동하여 스케줄링하기
- Ingestion을 수행하는 계정 권한을 최소화하기 위해 자체 메타데이터 추출 로직 개발하기
- Helm Chart, ArgoCD를 이용하여 GKE에 배포하기
아래는 Datahub 공식 사이트에서 제공하는 데모 사이트의 스크린샷입니다. 이 플랫폼이 완성되면 또 다른 글로 찾아오겠습니다 :)
 Datahub - 데모 메인 페이지.
Datahub - 데모 메인 페이지.
 Datahub - 데모 상세 페이지.
Datahub - 데모 상세 페이지.
각종 파티 참여
“파티”는 데이터 엔지니어링 팀에서 도입한 업무 형태입니다. 쉽게 말해 “중장기 프로젝트”라고 보시면 됩니다.
데이터 엔지니어링 팀에서 해결해야 하는 문제를 파티의 주제로 선정하고, 관련된 사람들이나 혹은 해당 주제에 관심 있는 사람들을 모아 킥오프를 합니다. 파티의 리더인 파티장은 팀원 중 한 명이 맡게 되며, 파티장을 돌아가면서 할 수도 있습니다.
파티는 여러 “시즌”이 있고, 한 시즌 안에는 여러 “액트(Act)”가 있습니다. 각자의 업무와 시간, 우선순위 등을 고려하여 필요한 일감을 시즌과 액트로 나누고 파티원들에게 일감을 분배합니다. 그리고 정기 회의를 통해 진행 상황을 리뷰하고 한 액트 혹은 시즌이 끝나면 회고하는 시간을 가집니다.
현재 데이터 엔지니어링 팀에서 진행하는 파티는 로그 시스템, 가격 시스템, 데이터 마트 등 여러 분야가 있습니다.
제가 현재 참여하고 있는 파티는 다음과 같습니다.
소다 스토어 파티 - 쏘카의 데이터를 깔끔하고 편리하게
- 소다 스토어는 쏘카의 데이터를 한눈에 볼 수 있는 데이터 마트입니다. 자세한 설명은 쏘카 데이터 그룹 - 데이터 엔지니어링 팀이 하는 일에서 볼 수 있습니다.
- 이 파티에서 쿼리의 확장성과 모듈화를 위해 dbt라는 도구를 소다 스토어와 관련된 쿼리에 적용하는 작업을 하고 있습니다.
- 또한 dbt를 적용하는 대부분의 과정을 자동화하는 CLI를 만드는 과정에 참여하고 있습니다.
 페어코딩 중 코드가 돌아가길 기도하고 있는 모습
페어코딩 중 코드가 돌아가길 기도하고 있는 모습
소다 로그 파티 - 쏘카의 모든 로그를 효율적으로 관리한다
- 쏘카의 모든 로그를 잘 가공하여 사용자가 잘 사용할 수 있도록 만드는 파티입니다.
- 이 파티에서 기존 레거시 서버에 있는 로그 적재용 Airflow DAG들을 Kubernetes 환경으로 안전하게 옮기는 일을 하고 있습니다.
온보딩 과정이 어떻게 도움 되었나요?
메타데이터 프로젝트에선 플랫폼에 메타데이터 주입 과정을 커스텀화 하기 위해서 Docker Image를 직접 빌드해야 했습니다. 온보딩 과제에서 Docker Image를 만들고 관련 명령어를 다뤄본 경험을 활용할 수 있었습니다. 그리고 이렇게 만든 Docker Image를 Airflow의 KubernetesPodOperator로 실행해 배포하는 과정도 필요했습니다. 이 과정 역시 온보딩 과제 중 간단한 Airflow DAG을 만들고 배포해본 경험에서 응용할 수 있었습니다.
또한 Datahub를 Helm chart를 이용하여 GKE에 배포해야 했습니다. 이 역시 온보딩 과제에서 Helm Chart로 GKE로 배포해보았던 경험이 도움 되었습니다. 물론 온보딩 때보다 Datahub의 차트가 훨씬 복잡했지만, 기본적인 플로우를 이해하고 있는 것이 큰 도움이 되었습니다.
소다 로그 파티에서는 기존 레거시 서버에서 쿠버네티스로 DAG을 옮기는 과정에서, Airflow DAG의 설정을 수정하고 GitHub Repository를 통해 DAG을 CI/CD 파이프라인으로 배포해야 했습니다. 이 과정에서도 Airflow 관련 온보딩 경험을 다시 한번 활용할 수 있었습니다.
결과적으로, 초기 업무를 할 때 온보딩 과제를 정리한 글을 20번 넘게 스스로 참고할 정도로 실질적인 도움이 되었습니다. 이렇게 보니 온보딩 과정이 없으면 정말 큰일 날뻔했네요 😂
4. 앞으로는 무엇을?
많은 분의 도움이 있었던 온보딩 기간을 거치고, 앞으로 회사에서 하고 싶은 것이 생겼습니다.
여러 사람이 편해지는 시스템이나 도구를 만들고 싶어요.
데이터 엔지니어링 업무 자체가 서포팅의 성격이 있습니다. 회사에서 저뿐만이 아니라 여러 사람이 편해지는 시스템이나 도구를 만들고 싶습니다.
예를 들면 “디니의 트러블슈팅 DB”를 만들고 있는데요. 지금 트러블슈팅한 과정을 미래의 나 혹은 다른 사람이 구글링처럼 편하게 검색하고 찾을 수 있었으면 좋겠다는 생각에서 시작되었습니다.
그리고 제가 온보딩 과정에서 도움을 많이 받은 만큼 다음 오시는 분을 위해 온보딩 과정을 더욱 발전시키고 싶습니다. 개인적인 경험으로는 ArgoCD를 통한 배포와, Python 협업 환경(테스트 코드 짜기, 디버깅 하기 등)에 대한 온보딩 등이 추가되면 더 좋겠다고 느꼈습니다.
문화 개선에 기여하고 싶어요.
함께 일하기 즐거운 회사가 되면 좋겠다는 소망이 있고, 제가 할 수 있는 것부터 하려고 노력 중입니다. 예를 들면 데이터 그룹 해피아워, 워크샵 등 밍글링 행사의 기획을 맡고 있고, “코딩 안풀릴때 소리지르는 방” 슬랙 채널 개설해서 다들 일하다 마음껏 소리지르는 (…) 공간을 만들었어요.
 입사 이후 최대의 업적 : 코딩 안될때 소리지르는 방 만든 것.
입사 이후 최대의 업적 : 코딩 안될때 소리지르는 방 만든 것.
많이 공유하고 싶어요.
취업 준비 할 때 쏘카 기술 블로그를 많이 참고하기도 했고 공부하면서 언제나 다른 사람의 글을 보며 배우고 있기 때문에, 항상 유용한 글을 쓰고 싶다는 마음이 있습니다. 곧 메타데이터 플랫폼 글로 돌아오겠습니다. 😏
5. Q & A
마지막으로 취업을 준비하면서 스스로 궁금했던, 그리고 비슷한 과정에 계실 분들이 궁금할만한 질문들과 이에 대한 답변을 정리해보았습니다.
실무에서 데이터 분석가(데이터 사이언티스트)와 데이터 엔지니어의 차이는?
데이터 분석가와 데이터 사이언티스트 분들이 맘껏 능력 발휘할 수 있는 탄탄한 플레이그라운드를 만드는 것이 데이터 엔지니어링의 역할인 것 같습니다. 취업 준비할 때는 데이터 관련 직군 간의 업무 차이가 잘 와닿지 않았는데, 실무를 경험해보니 담당하는 업무가 확연히 다른 것 같습니다. (물론 회사마다 정의가 다르고, 작은 규모에서는 같이 하시는 분들도 있을 것 같습니다)
아주 단순하게 얘기하자면 데이터 분석가는 말 그대로 ‘분석가’, 데이터 엔지니어는 ‘개발자’의 모습에 가깝다고 생각합니다. 어떤 목적을 해결하기 위해 데이터를 통해 분석하거나 사업적인 고민하는 것이 좋다면 데이터 분석을, 시스템 구축과 자동화, 프로그래밍 자체에 관심이 많다면 데이터 엔지니어링이 더 맞지 않을까 싶습니다.
비전공자, 문과라는 백그라운드가 회사에서 어떻게 작용하는지?
저도 이 점에 대해서 걱정했는데, 저희 팀에는 오히려 비전공자가 더 많고 중요한 건 아무도 과(와 학교)에 신경을 쓰지 않습니다. 그런 백그라운드보다 요구하는 일을 할 수 있는 실력이 더 중요하다고 느꼈습니다.
그리고 커뮤니케이션 능력은 어디서 무슨 일을 하든 무조건 플러스라고 생각합니다. 회사에 와서 보니 의사결정, 우선순위 산정 등 다른 게 더 중요할 수도 있다는 생각이 들었습니다. 배달의 민족 CEO 인터뷰에서 “개발자는 비즈니스 문제를 해결하는 사람”으로 정의하길 바란다는 말씀을 합니다. 이와 같이 코딩 뿐만 아니라 문제 해결에 지치지 않고 재밌어한다면 개발자가 잘 맞을 것 같습니다.
신입 데이터 엔지니어를 희망한다면 어떻게 포트폴리오를 꾸리면 좋을까?
개인적으로는 데이터 엔지니어링이 참 포트폴리오를 준비하기 힘든 분야라고 느꼈습니다. 소소하지만 저의 팁을 공유합니다.
1) 가고 싶은 회사가 어떤 환경인지 보고 공부하자.
가고 싶은 회사의 채용공고를 꼼꼼히 읽고, 어떤 툴과 프레임워크를 쓰는지 보시면서 그 프레임워크에 대한 공부를 하시면 좋을 것 같습니다
저희가 알고 있는 IT 기업들은 AWS, GCP, Hadoop 이 선에서 크게 달라지지 않는다고 생각합니다. 온라인 강의 사이트에서 이런 프레임워크를 타겟으로 한 강의를 참고하시면 좋을 것 같습니다.
쏘카 데이터 그룹은 기본적으로 GCP(Google Cloud Platform)를 이용하고 있기 때문에, 개인적으로 Qwiklabs 플랫폼의 GCP 관련 실습 강의(ex.Engineer Data in Google Cloud)가 많은 도움되었습니다. Hadoop의 경우 조금 오래된 강의지만 Udemy 플랫폼의 The Ultimate Hands-On Hadoop 강의를 통해 기본 개념을 익힐 수 있었던 기억이 납니다. 이 외에도 Udacity, O’Reilly 등의 강의 플랫폼에서 유용한 강의들을 찾으실 수 있습니다.
2) 나만의 작고 귀여운 ETL 파이프라인을 만들어보자.
데이터 엔지니어링 분야에서 가장 무난하게 포트폴리오를 만들 수 있는 것은 ETL 파이프라인이라고 생각합니다. 꼭 가고 싶은 회사의 프레임워크와 일치하지 않아도 상관없으니, 관심 있는 API 데이터를 ETL 하는 파이프라인을 만들어보면 관련된 아이디어를 발전시킬 수 있을 거라 생각합니다.
3) 블로그를 잘 관리하자.
신입 입장에서 이력서로 엄청난 차이를 보여주기는 쉽지 않다고 생각합니다. 이럴 때, 본인을 설명해줄 수 있는 개인 블로그나 포트폴리오 사이트가 있으면 좋습니다. 글이 완벽하지 않더라도 공부한 것들이나 관심있는 내용을 작성하면 좋은 것 같습니다.
여기까지 데이터 엔지니어링팀 디니의 4개월 신입 회고였습니다. 온보딩 과정을 도와주신 팀원분들 이 자리를 빌어 다시 한번 감사드립니다.
긴 글 읽어주셔서 감사합니다. 궁금한 점이 있으시면 언제든 댓글 남겨주세요 :)