 hardy
hardy안녕하세요. 데이터 엔지니어링팀의 하디입니다.
이번 글에서는 쏘카 데이터 그룹의 태동기(2018년)부터 현재(2021년)까지 어떻게 Airflow를 구축하고 운영했는지를 소개합니다. 특히 최근에 쏘카 데이터 그룹에 Kubernetes(정확히는 Google Kubernetes Engine)를 도입했는데, Kubernetes 위에서 Airflow를 어떻게 활용했는지에 대해 자세히 담아보려 노력했습니다.
이 글은 다음과 같은 분들을 대상 독자로 합니다.
- 데이터 그룹을 운영하고 계신 분
- 데이터 파이프라인 및 워크플로우 도구 도입을 고려하고 있으며, Airflow에 관심이 있으신 분
- Airflow를 기존에 사용하고 있으나, 상황에 따라 어떻게 더 활용해야 할지 고민하시는 분
- Kubernetes 환경 위에서 Airflow를 배포 및 운영을 고려하시는 분
이 글을 통해 다음과 같은 내용을 파악할 수 있습니다.
- 데이터 그룹의 상황에 따라 다양한 Airflow 구축과 운영하는 방법
- 데이터 그룹이 성장함에 따라 생기는 데이터 엔지니어링 이슈
- Kubernetes 환경의 Airflow 배포 및 운영 전략
목차
- 기존 환경 - Rundeck
- 태동기 - Google Cloud Composer
- 초창기 - Google Compute Engine + Docker Compose
- 고려 사항
- 의사 결정
- 배포 형태
- 운영 형태
- 문제점
- 성장기 - Airflow on Kubernetes
- 고려 사항
- 해결 방법
- 배포 형태
- 배포 방법
- 운영 형태
- 기타 추가 작업
- 성숙기를 향하여
- 마무리하며
- 참고한 자료
기존 환경 - Rundeck
데이터 그룹이 처음 설립된 2018년, 쏘카의 테크 조직들은 Task 스케줄링 도구로 Rundeck을 사용하고 있었습니다. 데이터 그룹에서도 이 Rundeck을 그대로 사용할지, 아니면 새로운 도구를 도입해볼지 고민했습니다. 이때 다음과 같은 요구 사항을 염두에 두었습니다.
- 데이터 파이프라인(ELT 혹은 ETL) 스케줄링 작업과 쏘카 서비스의 스케줄링 작업 분리를 시켜야 합니다.
- 쏘카 서비스와 관련된 스케쥴링 작업은 실제 고객을 대상으로 하는 작업이므로, 데이터 파이프라인보다 우선순위가 높습니다.
- 데이터 파이프라인 작업 때문에 기존 쏘카 서비스에 영향을 주어서는 안 됩니다.
- 데이터 파이프라인을 위한 다양한 기능이 제공되는 도구가 있으면 좋겠습니다.
- 쏘카는 데이터 웨어하우스로 BigQuery를 사용하고 있었으므로, BigQuery 및 클라우드와 쉽게 연동이 가능한 도구면 좋습니다.
- Workflow 시각화를 잘해주는 도구가 있으면 좋겠습니다.
- 많은 데이터 파이프라인이 만들어질텐데, 이 파이프라인들이 어떤 테스크를 수행하는지 한 눈에 확인 가능해야 합니다.
기존 Rundeck은 위와 같은 요구사항을 충족시키기엔 부족했기에, 새로운 도구를 도입하기로 결정했습니다. 결과적으로 당시 데이터 파이프라인 플랫폼으로 많이 쓰이는 Apache Airflow를 사용해보기로 결정했습니다.
태동기 - Google Cloud Composer
데이터 그룹이 생긴 태동기에는 데이터 엔지니어가 없었습니다. 데이터 분석가들이 직접 데이터 파이프라인을 만들어야 했습니다.
기술적인 이슈보다 당장 분석에 필요한 파이프라인을 만드는 것이 가장 높은 우선순위였습니다. 따라서 직접 구축 및 관리가 필요 없는 Google Cloud의 Cloud Composer를 사용하게 되었습니다.
Cloud Composer는 구글 클라우드에서 제공하는 Managed Airflow입니다. 참고로 현재 AWS에도 Managed Airflow(MWAA)가 존재하지만, 그 당시엔 구글 클라우드의 Cloud Composer가 유일했습니다. 또한 쏘카에선 데이터 웨어하우스를 구글 클라우드의 BigQuery로 사용했기 때문에 같은 구글 클라우드 서비스가 꽤 괜찮은 이점을 줄 거라 생각했습니다.

Cloud Composer는 정말 간단하게 사용할 수 있습니다. Airflow의 DAG 파일을 Cloud Storage에 업로드해서 사용합니다. Cloud Storage에 Airflow DAG 파일을 업로드하면 Cloud Composer에서 해당 파일을 읽어 작업을 실행합니다. 사용자 입장에서 Airflow 구성 요소에 대해 크게 신경 쓸 필요가 없이 DAG 파일만 잘 만들면 됩니다.
그러나 Composer는 종종 알 수 없는 에러를 발생시켰습니다. 당시 Airflow의 버전은 1.10.3로 오픈소스 자체에도 버그가 존재했습니다. 오류가 생겼을 때 로그를 직접 제대로 볼 수 없는 것이 1.10.3 버전의 가장 큰 문제였습니다. Composer의 안정성 문제와 로그와 관련된 이슈로 Composer를 계속 사용해야 하는가에 대한 고민이 시작되었습니다.
초창기 - Google Compute Engine + Docker Compose
데이터 그룹이 생긴 몇 달 뒤 데이터 엔지니어분들이 데이터 그룹에 합류하게 되었고, 자체 데이터 엔지니어링 팀이 탄생했습니다. 이제 데이터 엔지니어링팀에서 데이터 파이프라인 구축과 인프라 운영을 담당하게 되었고, 이전보다 좀 더 체계적인 데이터 분석 환경을 구축해볼 수 있게 되었습니다. 이제 Cloud Composer를 벗어나 데이터 엔지니어링 팀에서 Airflow를 직접 구축하고 운영하기로 하였습니다.
고려 사항
이 당시 고려한 사항은 다음과 같습니다.
- 빠르고 간단하게 배포할 수 있어야 합니다.
- 데이터 그룹의 누구나(데이터 분석가/데이터 사이언티스트, 데이터 엔지니어) 쉽게 DAG 작성이 가능해야 합니다.
- 운영이 수월해야 합니다.
데이터 엔지니어링 팀과 데이터 그룹이 크지 않기 때문에 간단하며 신속하고 유연하게 움직일 수 있는 방식을 고려했습니다.
의사 결정
고민 끝에 선택한 배포 방법은 Google Compute Engine 위에 Docker Compose로 Airflow의 각 컴포넌트(Webserver, Scheduler 등)를 직접 Docker 컨테이너로 띄우는 방법입니다. Github에 있는 puckel/docker-airflow 이미지를 이용하면 이를 쉽게 구현할 수 있었습니다.
또한 분석 팀원들에게 익숙한 Jupyter Notebook을 동일 환경에서 배포하고, Jupyter Notebook을 통해 Airflow DAG을 수정할 수 있도록 했습니다.
배포 형태
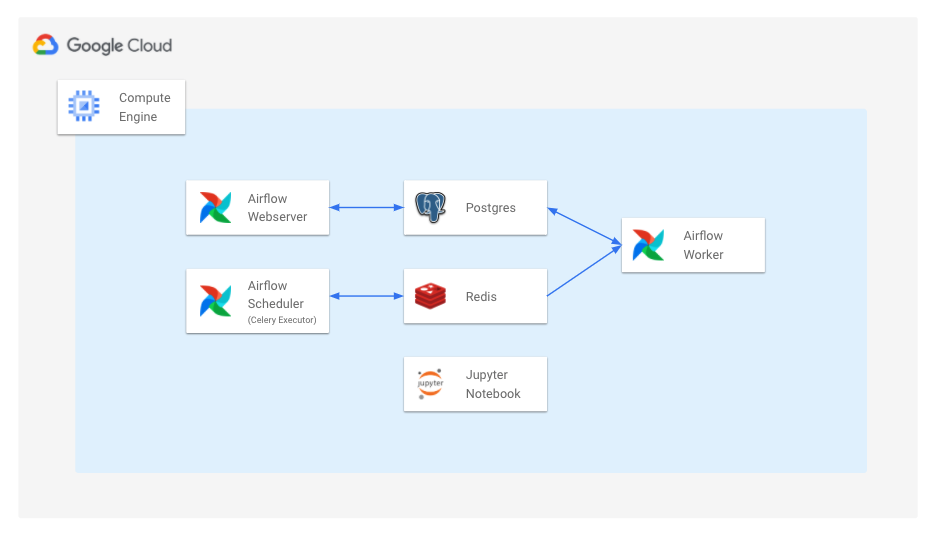
- Google Cloud Platform의 Google Compute Engine 인스턴스를 호스팅 서버로 사용합니다.
- Airflow의 각 컴포넌트인 WebServer, Scheduler, Database, Worker, Redis를 Docker Compose를 통해 각각 컨테이너로 실행합니다.
- Airflow Scheduler는 Celery Executor를 사용합니다.
- Jupyter Notobook을 Docker 컨테이너로 띄운 뒤 Airflow DAG 폴더에 Volume Mount합니다.
이렇게 하면 Airflow의 각각의 컴포넌트에 대해 통제가 가능해집니다. (Docker Container 재시작, 버전 업데이트, 로그 등)
운영 형태
Google Compute Engine에 배포 후, 다음과 같은 방법으로 Airflow를 사용했습니다.
- DAG 작성자는 Jupyter Notebook 웹에 접속해 DAG을 작성합니다.
- Jupyter Notebook을 통해 쉽게 코드 작성이 가능합니다.
- Volume Mount 되어 있기 때문에 저장하면 몇 초 내로 Airflow에 반영됩니다.
- Airflow의 Connections에 BigQuery 설정을 저장해 재사용 가능하게 합니다.
- 이런 설정을 저장하는 일은 주로 데이터 엔지니어링팀에서 담당합니다.
- DAG 작성자는 저장한 설정을 사용합니다.
위와 같은 방식은 Airflow를 간단하게 배포할 수 있었고, 운영 역시 어렵지 않았습니다. 그러나 조직과 서비스가 점점 성장하면서 여러 문제점이 보이기 시작했습니다.
문제점
1) 늘어나는 DAG
데이터와 서비스가 성장하면서 DAG의 수도 점점 늘어났습니다. DAG의 수가 늘어나다 보니 DAG의 실행 속도도 점점 느려지고, 제시간에 실행되지 않고 시작 시간이 밀리는 경우도 발생했습니다. 특히 배치 주기가 짧은 DAG에서 이런 현상은 매우 심각한 문제였습니다.
이런 경우에 할 수 있는 일은 Google Compute Engine의 머신 유형을 한 단계 업그레이드(컴퓨팅 리소스를 수직 확장, Scale Up)하는 방법뿐이었습니다. 그러나 이 방법을 선택해도 DAG이 실행되는 특정 시간 외에는 리소스를 쓰는 일이 거의 없기 때문에 리소스 사용 효율 측면에서는 매우 비효율적입니다. 리소스를 유연하고 효율적으로 사용할 수 있는 방법에 대해 고민이 들기 시작했습니다.
2) 규칙 없이 제각각으로 작성된 DAG 코드
- 여러 사람이 모두 제각각의 스타일로 작성한 DAG을 작성하였습니다. 예를 들어 어떤 DAG에는
on_failure_callback값이 있는 반면, 어떤 DAG들은 이 값들이 보이지 않았습니다. - Jupyter Notebook 환경에서 코드를 작성하다 보니 PEP8과 같은 스타일 컨벤션을 잘 지키긴 어려웠습니다.
- 가장 큰 문제는 DAG 코드가 담긴 모듈 이름에 규칙이 없어서, Airflow 웹에서 문제가 생긴 DAG이 실제로 어떤 파일인지 찾기 쉽지 않았습니다.
- DAG 파일을 언제 생성했고 수정했는지에 대한 히스토리가 없어서 문제가 생겼을 때 원인을 찾기 어려웠습니다.
일관된 DAG의 템플릿과 PEP8과 같은 코드 스타일 규칙의 필요성이 느껴졌습니다. 또한 코드 변경을 추적할 수 있도록 버전 관리 도구(Git 등)의 필요성을 느끼기 시작했습니다.
3) 복잡해지는 의존성 문제
Airflow의 버전이 바뀌면 기존 DAG코드도 변경해야 하는 문제가 있습니다. Airflow 버전은 생각보다 빠르게 업데이트되었고, 그때마다 의존성/안정성의 문제로 쉽게 Airflow의 버전을 올리기 어려웠습니다.
그리고 일부 DAG에서 requests 나 beautifulsoup4, lxml 와 같은 라이브러리를 사용하는 경우가 있습니다. 이런 경우 Airflow Webserver, Scheduler, Worker 컨테이너에 모두 라이브러리를 설치해야 했습니다. 설치된 Airflow 버전과 호환이 되어야 했기 때문에 파이썬 버전도 신경 써야 했습니다. 이렇게 가다간 흔히 말하는 의존성 지옥에 빠질 거 같았습니다.
Airflow, 라이브러리, 파이썬 버전 등 점점 복잡해지는 의존성을 더 쉽게 해결할 방법을 찾아야 했습니다.
4) 운영과 테스트의 혼재
이 당시 Airflow상에 있는 DAG은 대부분 Data Lake나 Data Mart를 만드는 파이프라인이 많았고, 이 파이프라인들의 목적지는 주로 BigQuery였습니다. 대부분의 DAG 작성자들은 파이프라인이 잘 작동하는지 테스트하기 위해 BigQuery의 최종 테이블 이름 끝에 _test 를 붙여서 실행하는 경우가 많았습니다. 이렇게 실행 후, 테스트한 데이터셋을 지우지 않는 경우가 많아 BigQuery에 _test 로 끝나는 테이블들이 너무 많이 생기게 되었습니다.
그리고 테스트하는 과정에서 실제 운영 중인 테이블에 직접 접근하는 로직이 포함된 DAG이 있는데, 이 DAG들이 가장 큰 문제였습니다. 예를 들어 DAG 작성자가 BigqueryOperator 를 사용해 테스트할 때, 깜빡하고 테이블 이름 끝에 _test 를 붙이지 않고 DAG을 실행하는 경우, 실제 운영되는 테이블을 덮어쓰거나 과거 데이터를 날려버릴 수 있습니다.
운영 환경과 격리되어 안전하게 테스트할 수 있도록 별도의 개발 환경이 필요했습니다.
성장기 - Airflow on Kubernetes
데이터 그룹이 생긴 이후 2년 동안 회사는 빠르게 성장했고, 데이터 그룹의 인원도 7명에서 27명으로 늘어나게 되었습니다. Airflow에서도 다양한 DAG이 생기게 되었고, 그 개수는 600개를 넘어섰습니다. 또한 데이터 그룹의 데이터 분석가 모두 Airflow DAG을 작성할 수 있었기 때문에 DAG을 작성하는 사람들도 많아지고, 사용하는 Operator도 더 다양해졌습니다. 더 많은 리소스가 필요하게 되었고, 관리할 포인트가 점점 더 생겼습니다.
고려 사항
위에서 생긴 문제들을 해결할 방안을 생각해야 했습니다. 구체적으로는 다음 관점으로 Airflow 고도화에 대해 생각했습니다.
- DAG이 늘어나도 실행 시간이 늘어나거나 지연이 없도록 리소스를 유연하게 확보 및 할당할 수 있어야 합니다
- 깔끔하고 일관된 DAG 코드와 파라미터값을 표준화해야 합니다
- Airflow와 파이썬, 파이썬 라이브러리의 의존성을 최대한 낮춰야 합니다
- 운영 환경에 영향을 주지 않고 테스트 가능한 별도의 환경이 필요합니다
해결 방법
다양한 고려 사항을 기반으로 다음과 같은 해결 방법을 세우고, 하나씩 도입하기 시작했습니다.
- 단일 컴퓨팅이 아닌 Kubernetes를 도입합니다.
- Node Auto Scaling을 적용해 필요에 따라 리소스를 유연하게 확보하고 할당할 수 있습니다.
- 사용할 노드 풀을 직접 관리하기 때문에 CPU, GPU 사용량이 높은 파이프라인을 실행하기 좋습니다.
- Airflow 외에도 데이터 그룹에 필요한 다른 서비스들도 이 클러스터에서 관리할 수 있습니다.
- Airflow를 1.10.14 버전으로 업데이트하고, Kubernetes Executor를 사용합니다.
- Task 단위로 Pod을 생성하기 때문에 동시에 여러 Task를 빠르게 실행할 수 있습니다.
- Node Auto Scaling이 적용되어 있어 DAG이 늘어나도 리소스로 인한 실행 속도에 문제가 없습니다.
- 특정 환경(라이브러리, 파이썬 버전 등)의 의존성이 강한 DAG은 KubernetesPodOperator를 사용합니다.
- KubernetesPodOperator는 Airflow 1.10.x 버전부터 등장한 오퍼레이터로, 파라미터로 컨테이너 이미지를 입력받고 해당 이미지를 실행합니다.
- 즉 실행할 프로그램을 Airflow에 의존성 없이 개발할 수 있고, 이를 컨테이너 이미지로 잘 말아두면 KubernetesPodOperator로 실행할 수 있습니다.
- DAG 코드 작성에 규칙을 생성합니다.
- DAG 템플릿을 추상화해서 몇 개만 입력하면 DAG 코드를 생성할 수 있는 CLI를 생성했습니다. 이 CLI를 사용해 규격화된 DAG 파일을 생성합니다.
- Code Formatter로 Black을 사용하고, CI 과정에서 포매팅을 검사합니다.
- DAG 코드를 Git과 Github로 버전 관리 합니다.
- 누가 언제 어떤 코드를 추가, 변경했는지 관리할 수 있습니다.
- 코드 리뷰를 통해 보다 나은 DAG 코드를 유지합니다.
- 개발용 Google Cloud Platform 프로젝트에 격리된 테스트용 Airflow 환경을 만듭니다.
- DAG 코드가 담긴 Github Repository의 브랜치에 따라 동적으로 테스트용 Airflow를 배포합니다.
- 예를 들면
feature/hardy라는 브랜치를 만들면hardy용 Airflow가 배포됩니다. - 이런 방식으로 자신의 DAG을 테스트할 Airflow를 할당받을 수 있습니다.
- 격리된 환경이기 때문에 다른 사람의 작업 내용에 영향받지 않고 작업할 수 있습니다.
- 예를 들면
- 개발 환경에서는 운영 BigQuery에 READ만 가능하도록 합니다.
- 자세한 내용은 아래에서 더 설명하겠습니다.
- DAG 코드가 담긴 Github Repository의 브랜치에 따라 동적으로 테스트용 Airflow를 배포합니다.
Kubernetes 환경을 도입하면 여러 장점이 많아지지만, 운영의 복잡도와 난이도가 높아집니다. 2년 전과 비교해 Cloud Composer도 많이 성숙해졌고 AWS MWAA도 등장해 이 서비스를 다시 활용하는 것도 고려해보았으나, 데이터 그룹에서 사용할 Kubernetes 클러스터를 직접 만들고 이 위에서 여러 서비스를 운영하기로 결정했습니다.
데이터 엔지니어링 팀도 점점 커지고 있어 관리할 수 있는 사람이 많아졌고, 점점 더 복잡해질 인프라 구축에 맞서서 노력할 준비가 되어있었습니다.
배포 형태(운영 환경)
운영과 개발 환경의 배포 형태가 미세하지만 다르게 만들었습니다.
먼저 운영(Prod) 환경은 개발(Dev) 환경과 다른 별도의 Google Cloud Plaform 프로젝트에서 구성됩니다.
형태는 다음과 같습니다.
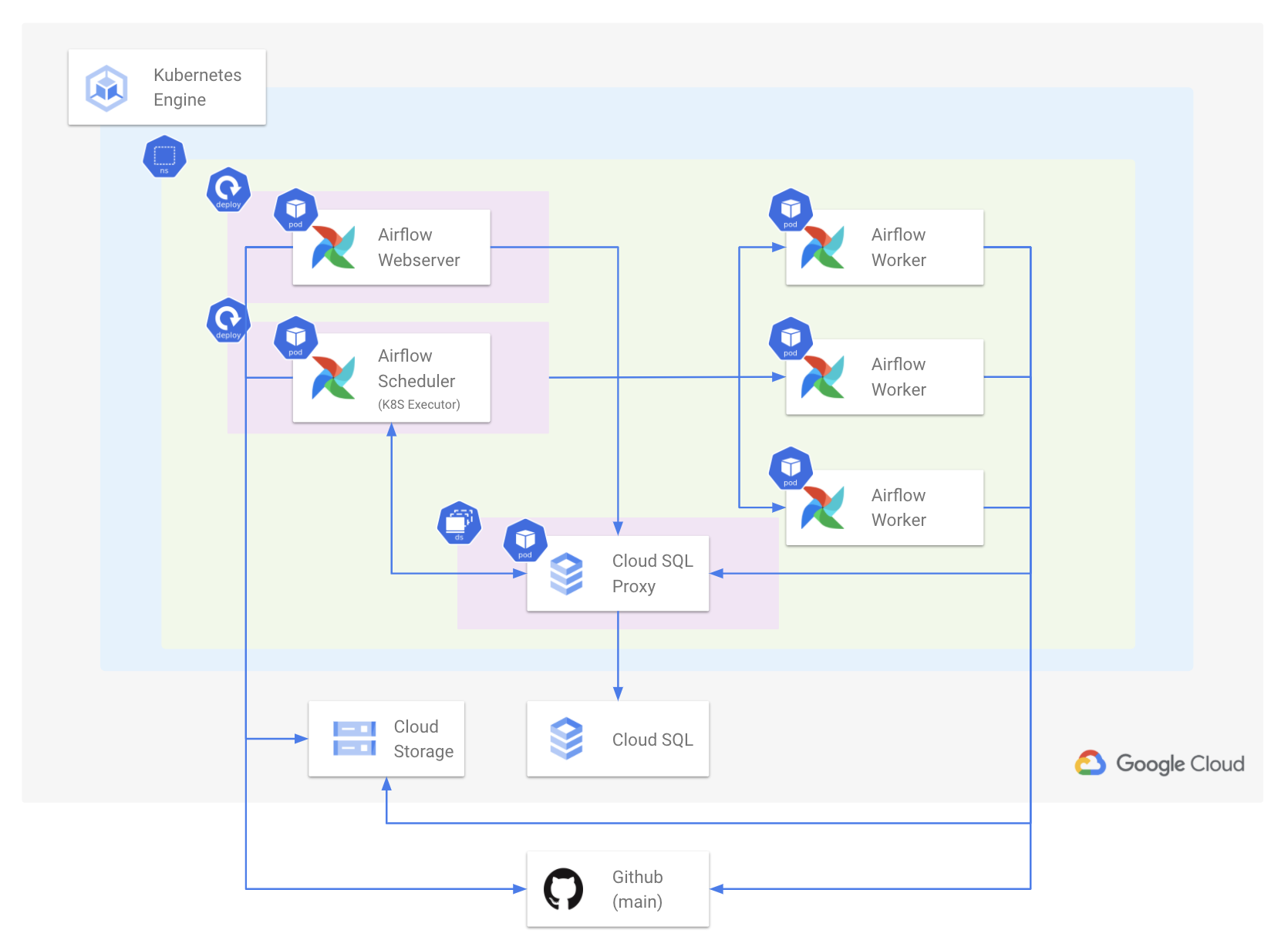
- GKE(Google Kuberentes Engine)에 별도의 Namespace 위에 Airflow가 배포됩니다.
- Scheduler는 Kubernetes Executor를 사용합니다.
- Airflow 컴포넌트는 Webserver, Scheduler, Database, Worker만 필요하게 됩니다.
- 각 컴포넌트는 Pod 단위로 배포됩니다.
- Worker Pod는 DAG 내 Task 단위로 동적으로 생성되었다가 내려갑니다.
위에서 핵심 컴포넌트들을 하나씩 살펴보겠습니다.
1) External Database(Cloud SQL) 사용
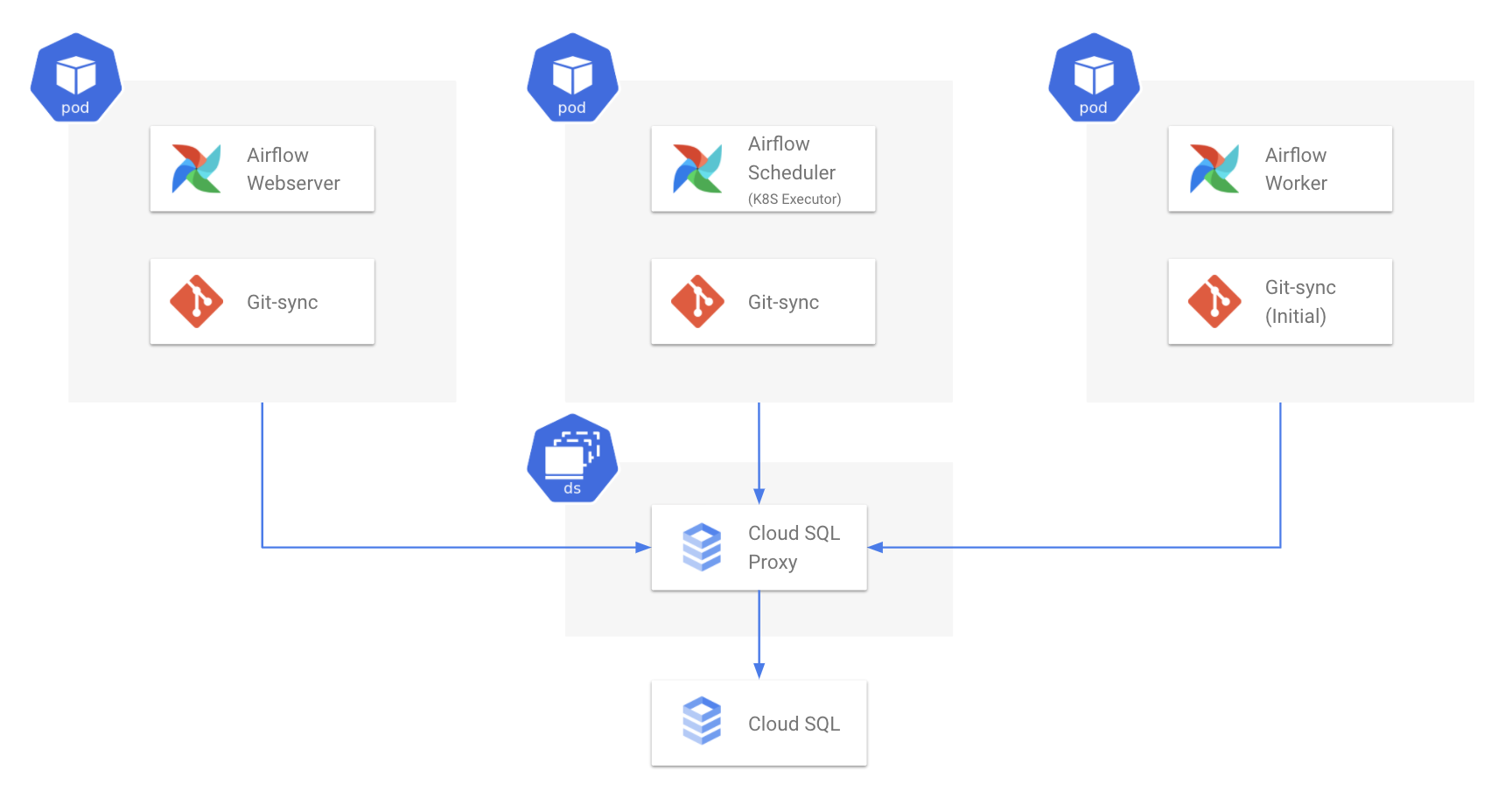
Airflow 컴포넌트 중 하나인 Database는 Stateful 하므로, Kubernetes 내부에서 관리하는 것보다 Kubernetes 외부에서 운영하는 것이 더 적합하다고 생각했습니다. 다양한 Database 중 Cloud SQL이 Google Cloud Platform에 있기에 활용하기 수월할 것으로 판단했습니다. GKE 내부에서는 Cloud SQL과 통신하기 위해 Cloud SQL Proxy를 Daemonset 형태로 배포합니다. Airflow는 이 Proxy를 거쳐 Kubernetes 외부 Database와 통신하게 됩니다.
이렇게 하면 Airflow가 Kubernetes에서 무슨 일이 생기거나, 재배포되어도 데이터는 여전히 남아있게 됩니다.
2) DAG을 담는 Github Repo 생성 및 Git-sync
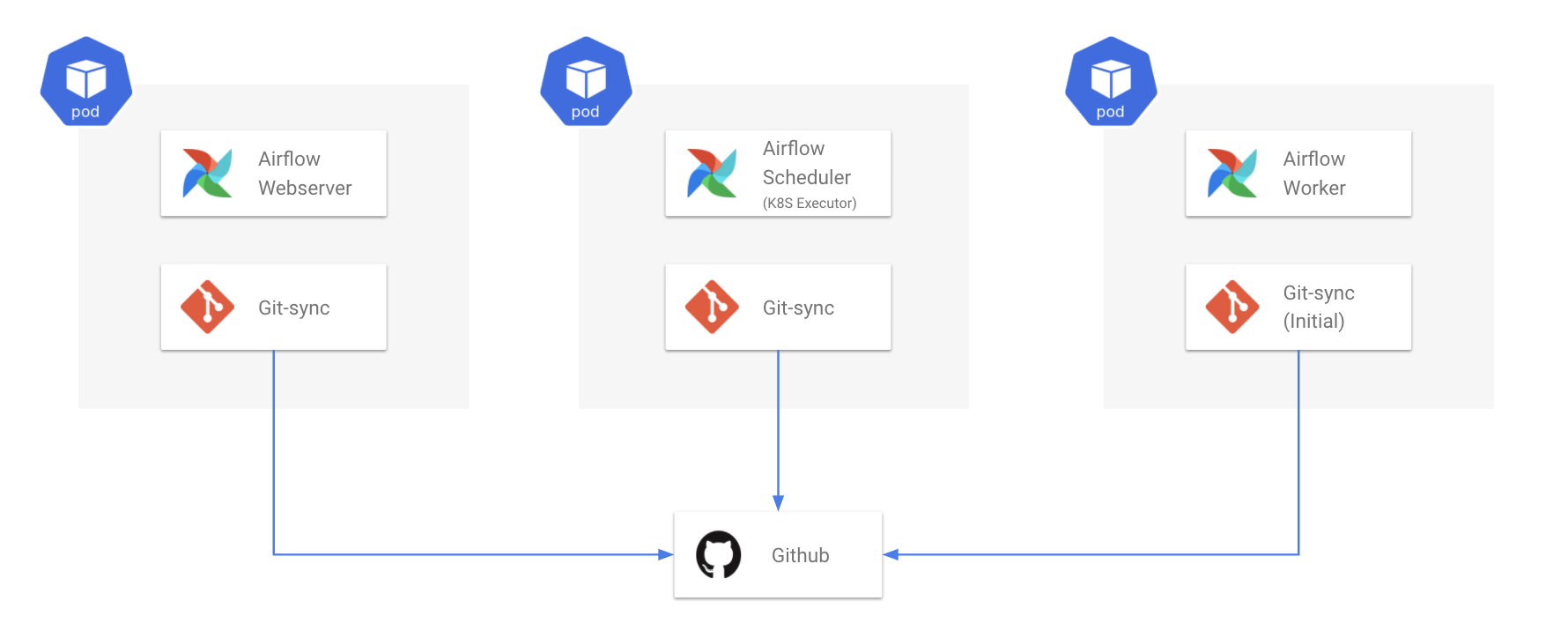
Github Repository에 DAG들을 저장합니다. 운영 환경에 반영되는 DAG들은 main 브랜치에 담습니다.
Webserver, Scheduler Pod 내부에 Git-sync는 주기적으로 이 Github Repository를 Pull합니다. Worker의 경우 처음에만 (Initial Container) Clone합니다. Git-sync가 Pull 혹은 Clone한 리포지토리는 Airlfow DAG 폴더에 마운트되어 있습니다. 따라서 Git-sync 작동에 따라 Airflow DAG 폴더가 주기적으로 업데이트됩니다.
3) Remote Logging(Cloud Storage) 사용
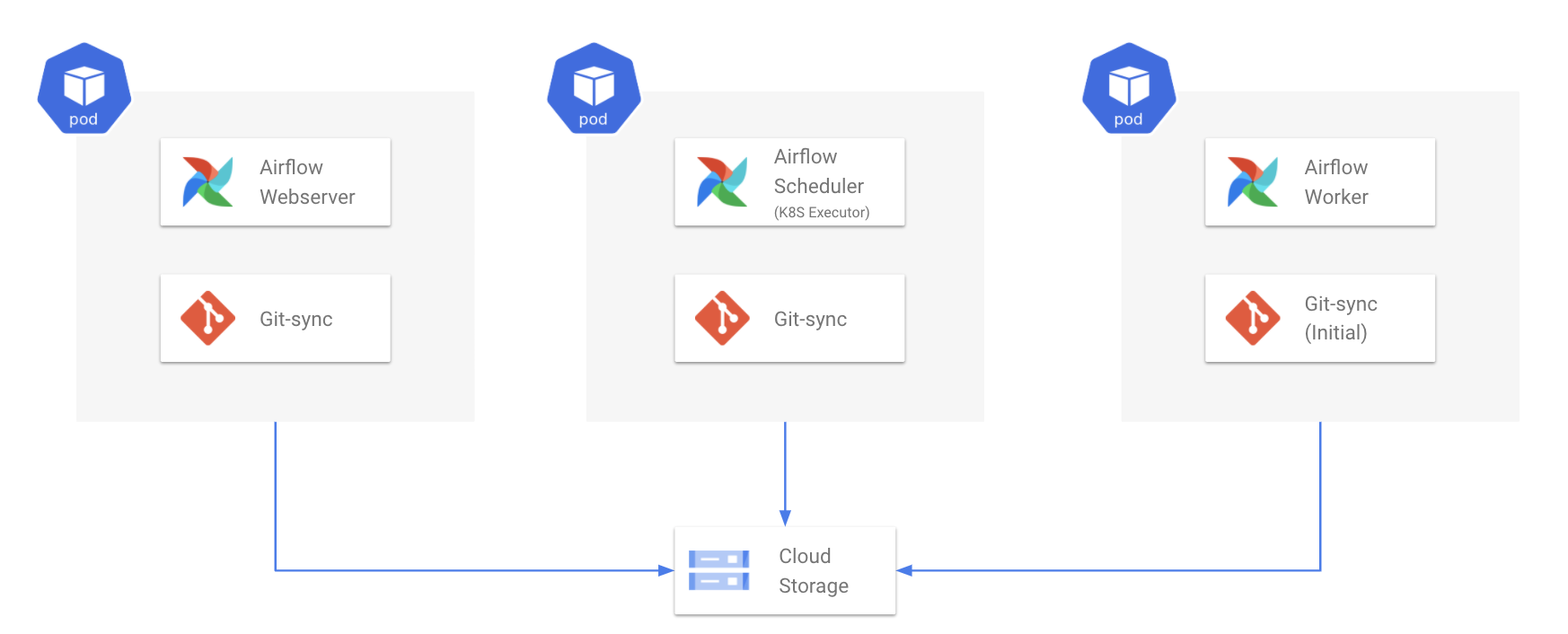
각 Airflow 컴포넌트가 Pod 단위로 배포되므로, Pod간 공유할 수 있는 별도의 로그 저장소가 필요합니다.
이를 위해 Airflow의 AIRFLOW__CORE__REMOTE_LOGGING 값을 True로 두어 Remote Logging 기능을 사용합니다.
Worker Pod에서 발생하는 로그 파일들은 모두 Cloud Storage에 저장되고, Airflow에서도 이 파일을 읽어서 Webserver에서 출력합니다.
4) Kubernetes Executor 사용
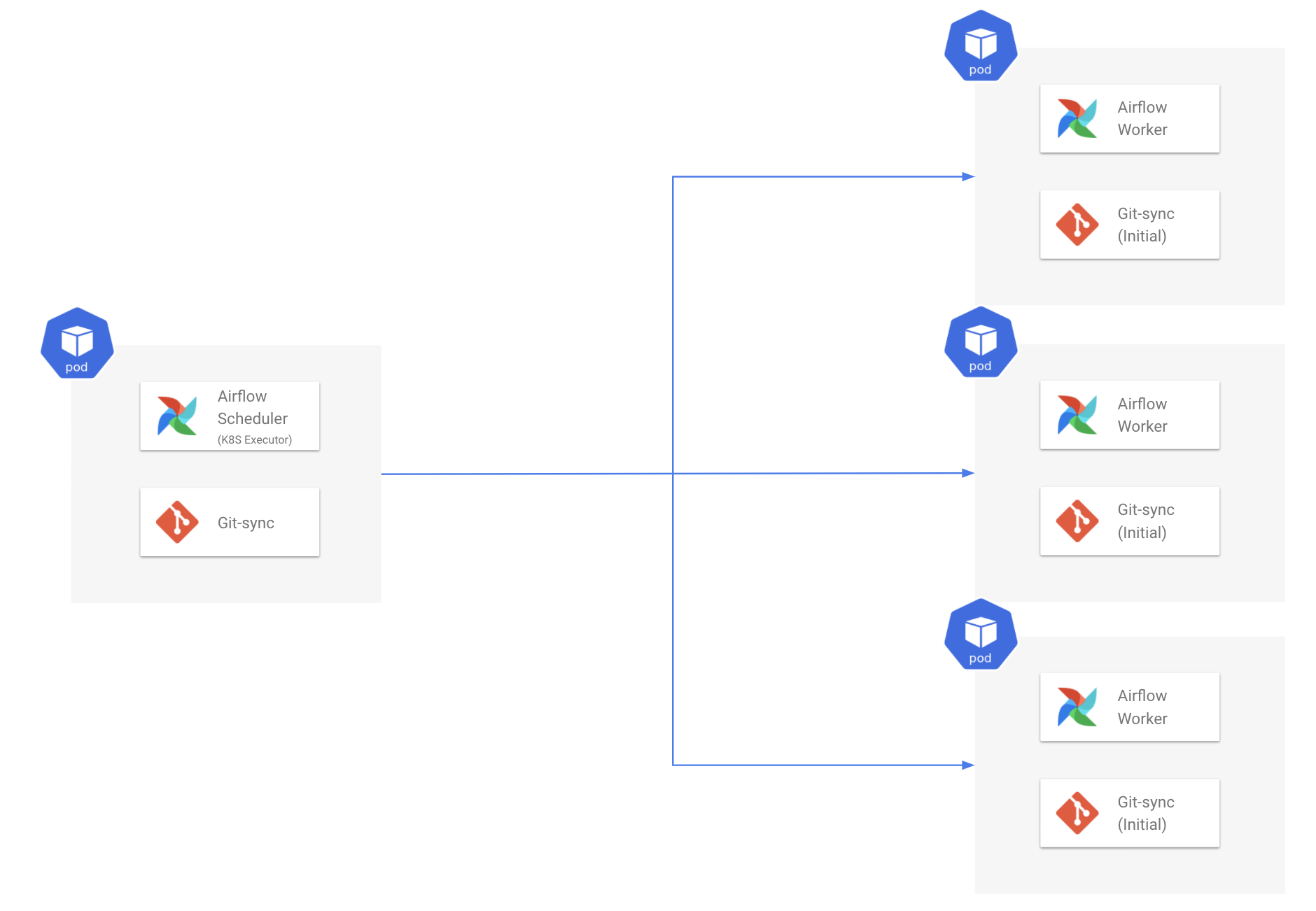
Kubernetes Executor를 사용하면 Worker를 Pod 형태로 동적으로 생성하게 됩니다. DAG이 실행될 때 Task 하나당 하나의 Worker Pod가 배포 및 실행된 후 삭제됩니다. 실행할 DAG이 없는 경우 Kubernetes 위에 Worker Pod이 존재하지 않습니다.
즉, 실행할 Task가 없을 때는 리소스 사용이 줄었다가 실행할 Task가 생기면 필요한 만큼 리소스를 할당하고 사용합니다. 결과적으로 리소스를 더 유연하고 효율적으로 사용합니다.
배포 형태(개발 환경)
개발 환경은 운영 환경과 별도의 Google Cloud Platform 프로젝트에 구성됩니다.
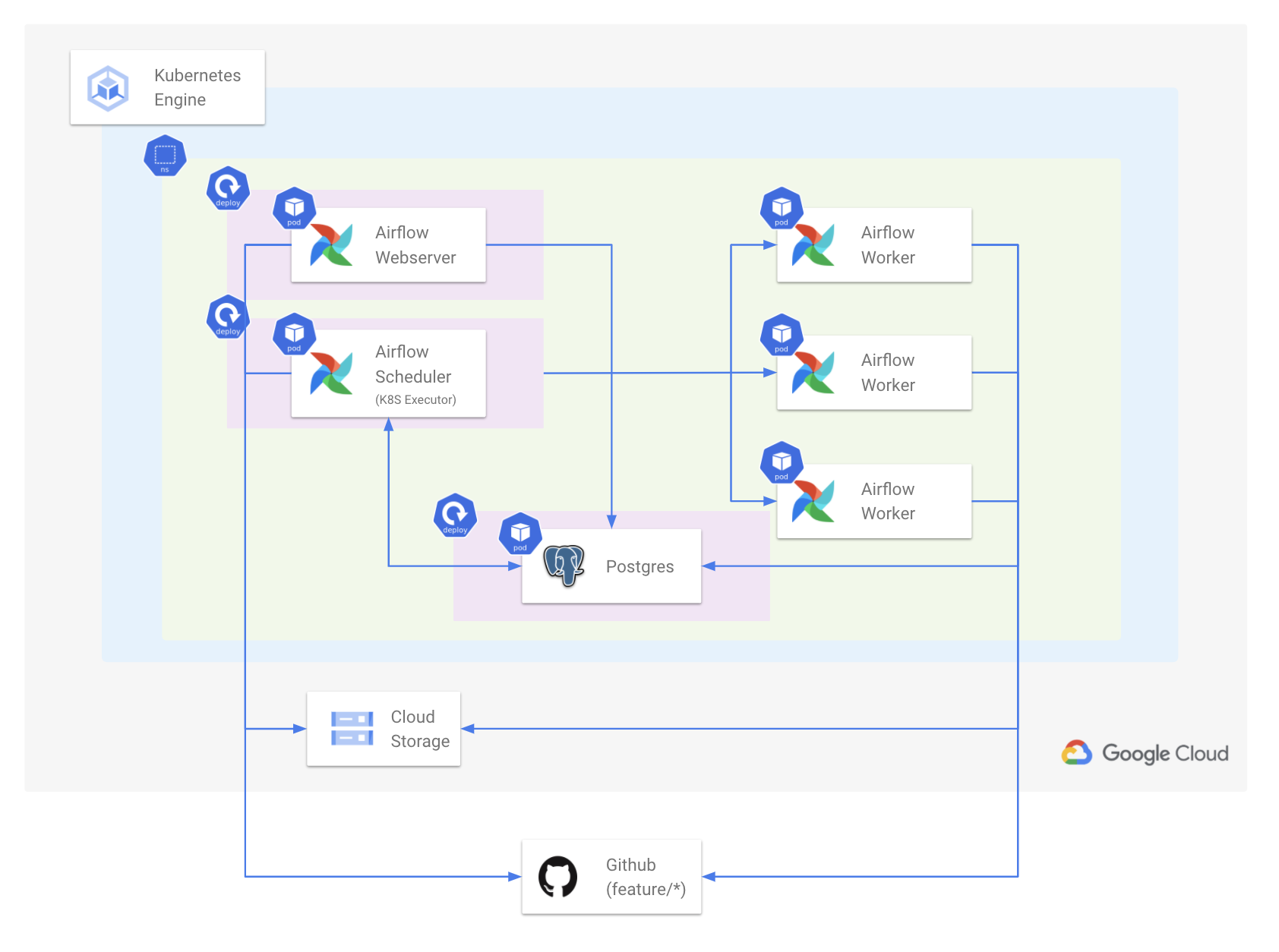
전반적으로 운영 환경의 배포와 동일합니다. 다만 DB가 Kubernetes 외부 Database가 아닌 Kubernetes 내부 Database입니다.
개발 환경의 Airflow는 항상 배포되어 있지 않고, DAG Github 리포지토리에 feature/ 로 시작하는 브랜치가 생성될 때 동적으로 배포되었다가 브랜치 삭제하는 시점에 내려갑니다. 즉 개인이 DAG 작업할 때에만 테스트하기 위한 용도로 배포되는 방식입니다. 테스트를 완료한 이후에는 테스트에 사용된 DB 역시 삭제해야 하기 때문에 외부 DB가 아닌 Kubernetes 내부 DB를 사용했습니다.
배포 방법
Kubernetes 클러스터에 App 배포는 ArgoCD를 사용하고 있습니다. ArgoCD는 GitOps 형태로 Kubernetes에 App을 배포할 수 있는 CD 도구입니다.
Kubenetes에 배포할 Helm 차트를 별도의 Github Repository에 보관합니다.
(차트는 커뮤니티 버전의 Airflow 차트 7.7.0 버전을 기반으로 커스터마이징했습니다.)
이후 ArgoCD Webserver에서 이 Github Repository와 연결을 맺도록 설정합니다. 그리고 App을 배포합니다. (ArgoCD로 App을 배포하는 방법은 커피고래님 블로그 글을 참고하시면 좋습니다)
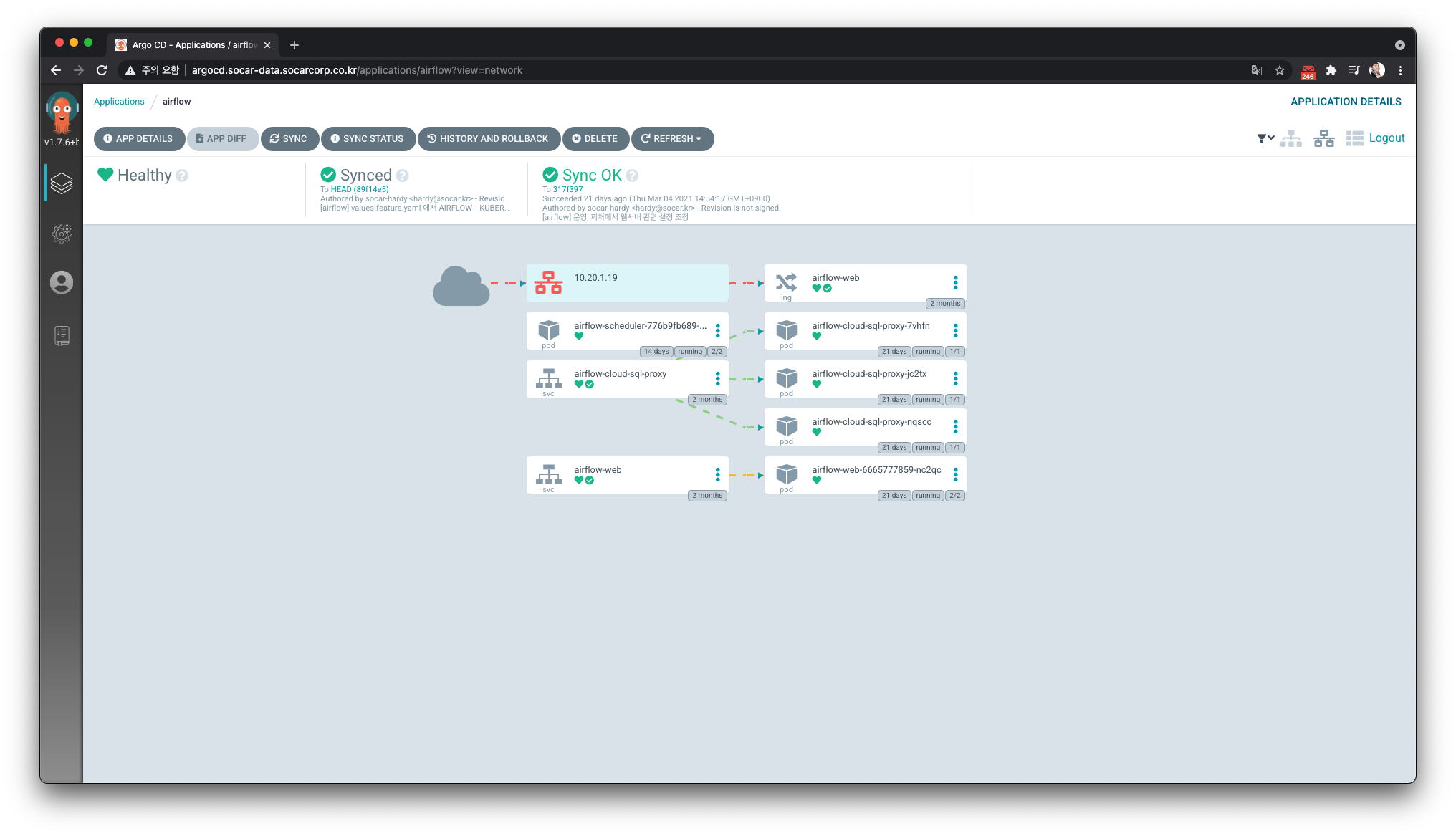
운영 형태
1) DAG 작성 프로세스
이제 Jupyter Notebook으로 DAG을 작성하지 않습니다.
각자 개인의 컴퓨터(로컬)의 IDE와 Git branch를 통해 DAG을 작성하고 Github Repository에 Push합니다. 위에서 설명한 것처럼 Repository에 Push하면 자동으로 브랜치별로 Airflow가 생성되어 DAG을 확인할 수 있습니다.
DAG을 작성할 때, 엔지니어링팀에서 만든 CLI를 사용합니다. 이 CLI는 Boilerplate를 생성할 수 있는 도구입니다. CLI에서 DAG 파일 이름이나 dag_id 생성 규칙이 담겨있습니다. 이런 방식을 사용해서 DAG의 기본 모양새를 일관성 있게 관리할 수 있고 DAG 작성자 관점에서도 고민없이 쉽게 DAG을 생성할 수 있습니다.
DAG 작성 및 테스트 후에는 main 브랜치로 Pull Request를 보냅니다. 데이터 그룹의 다른 팀원들의 리뷰를 받은 후 본격적으로 공용 브랜치인 main 에 자신이 만든 DAG이 합류하게 됩니다.
좀 더 구체적인 프로세스를 설명드리면 다음과 같습니다.
- DAG 작성자는 먼저 DAG을 저장하고 있는 Github Repository를 Clone 받습니다.
- 본인이 작업할 브랜치 (
feature/*)를 만들고 DAG Boilerplate CLI로 DAG을 작성합니다.- 예를 들면 브랜치 이름을
feature/hardy으로 설정합니다.
- 예를 들면 브랜치 이름을
-
Github remote origin으로 push 합니다.
$ git push origin feature/hardy - Github에 새로운
feature/*브랜치가 생성되며, 본인이 작업할 수 있는 Airflow가 할당됩니다.- 이 Airflow는 개발 환경에 배포되며, 본인이 작업하는 Github 브랜치와 동기화됩니다.
- 위 예시에선
airflow.socar-data/feature/hardy로 접속할 수 있습니다.
- 본인이 할당받은 Airflow에서 테스트를 마친 후
main브랜치로 Pull Request를 보냅니다.- CI 파이프라인에서 코드가 Black으로 포매팅되어있는지 확인합니다.
- 여러 팀원들에게 리뷰를 받은 후 최종적으로 Squash & Merge합니다.
- Branch가 삭제되면 할당받은 Airflow도 삭제됩니다.
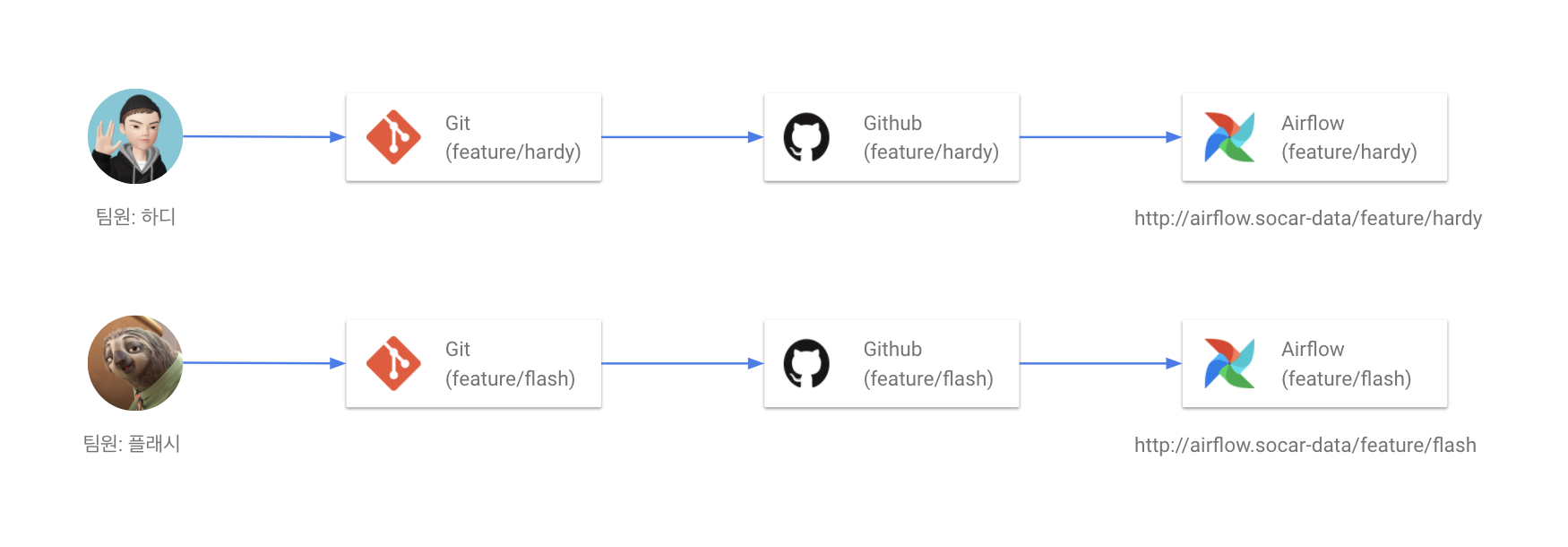
* DAG Boilerplate CLI 도구
DAG 작성자가 처음에 DAG 작성을 어떻게 할지 모르거나 당장 뼈대가 되는 코드가 필요한 경우, 비슷한 다른 DAG 코드를 복사해 사용하는 경우가 많았습니다. 그러나 다른 비슷한 DAG을 찾는 것도 번거롭고, 무엇보다 다른 DAG 코드의 형태에 의존하다 보니 DAG의 기본 형태가 일관되지 않았습니다.
이 때문에 DAG의 기본 형태를 규칙적으로 만들어주는 별도의 CLI 도구를 만들었습니다.
다음처럼 이 도구를 사용할 수 있습니다. (실행 결과로 DAG 파일을 만들어줍니다.)
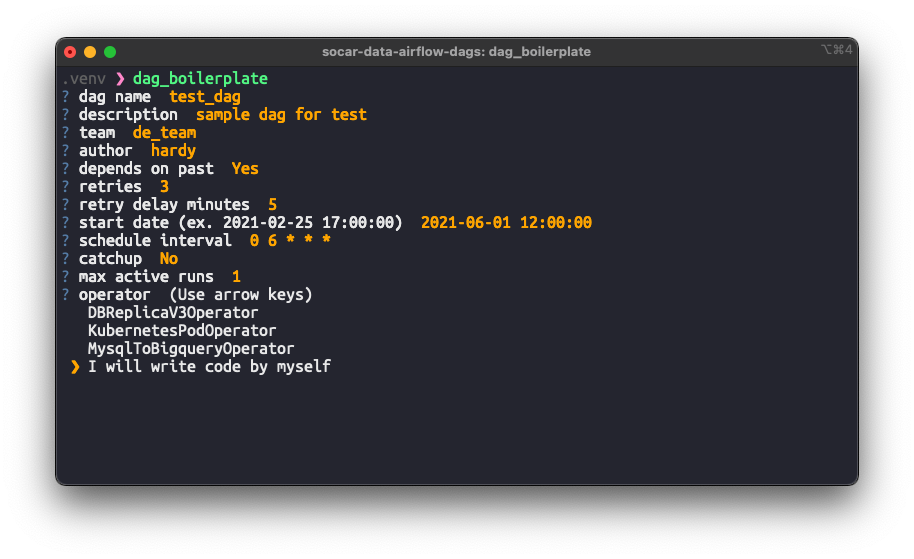
2) Airflow CI/CD
위와 같이 DAG 작성자의 feature/* 브랜치에 기반한 Airflow를 할당하기 위한 CI/CD 파이프라인은 다음과 같습니다.
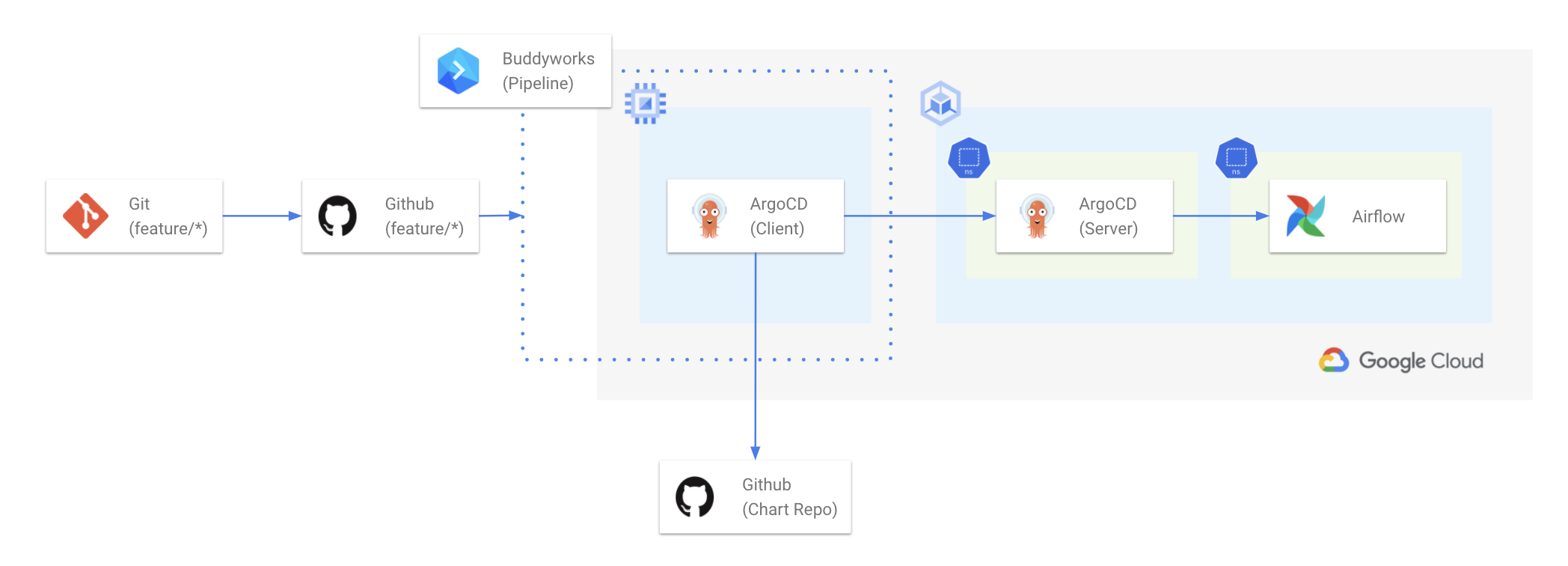
- Github Repository Webhook에서 Branch 생성 및 삭제하는 경우, CI/CD 파이프라인이 동작하는 트리거를 생성합니다.
- 쏘카에선 쉽게 CI/CD 파이프라인을 구축할 수 있는 BuddyWorks를 사용하고 있습니다.
- Branch 생성 시 BuddyWorks 내 파이프라인에서는 다음과 같이 실행됩니다.
- 클러스터와 통신할 수 있는 Bastion Host에 ssh 접속합니다.
- Bastion Host에서 ArgoCD Client를 통해 클러스터에 배포되어있는 ArgoCD Server에 로그인합니다.
- ArgoCD Client로 현재 HEAD branch와 연동된 Airflow 앱을 배포합니다.
- Branch 삭제 시, 같은 방법으로 위에서 생성된 Airflow 앱을 삭제합니다.
CI/CD 파이프라인 동작 모니터링은 Slack 채널을 통해 알람을 받습니다.

3) 리소스 모니터링
Kubernetes에서 동적으로 Airflow를 운영하다보니, 리소스 모니터링이 또한 중요하게 되었습니다.
아직 모니터링을 고도화하지는 않았지만 KubeLens와 Grafana로 모니터링하고 있습니다.
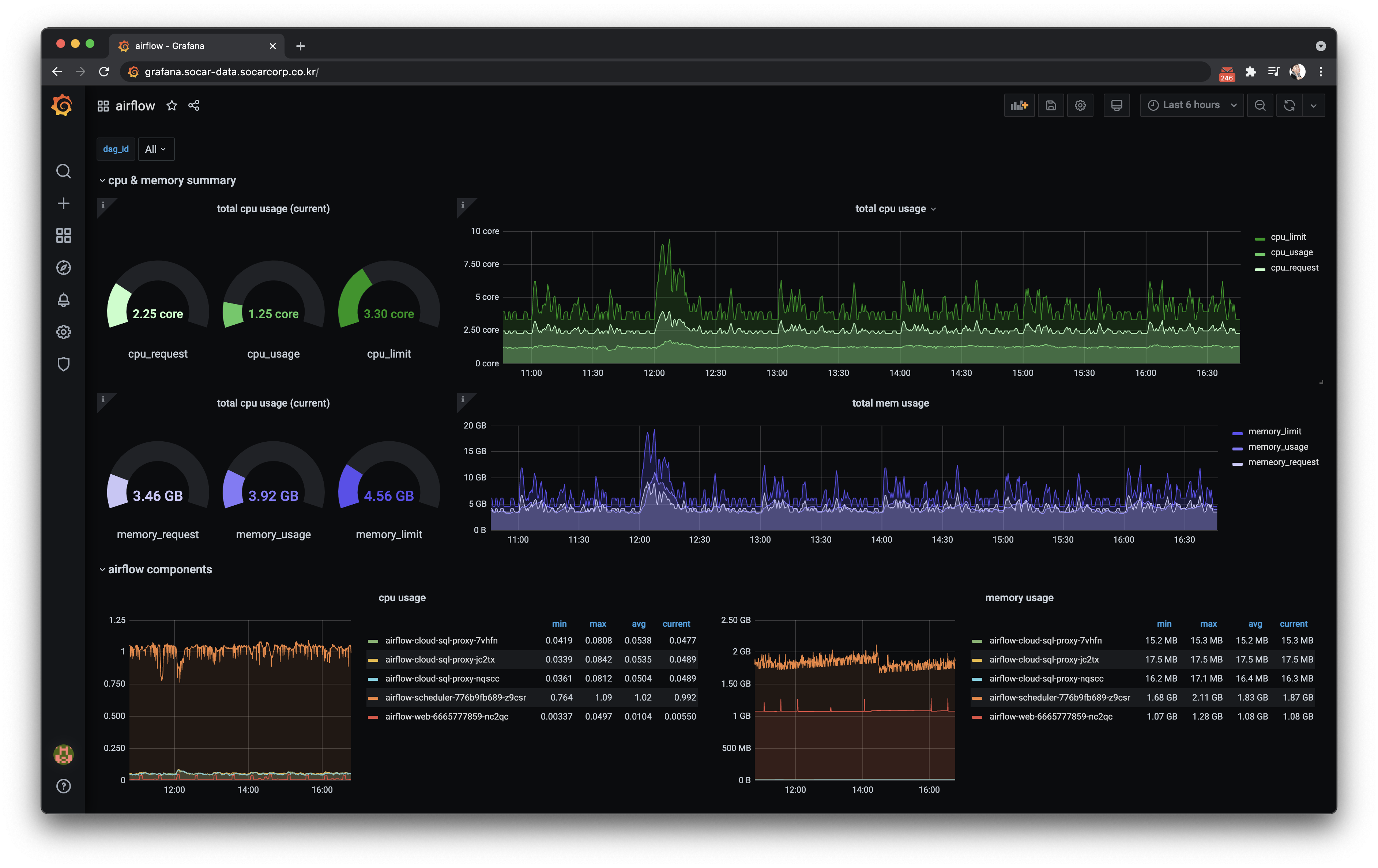
기타 추가 작업
Airfow를 더 커스터마이징해서 사용하기 위해 Airflow 1.10.14 버전을 Clone 받아 일부 코드를 아래 내용처럼 수정했습니다.
1) Pod 이름 생성 로직 수정
Airflow 1.10.14 버전을 그대로 사용하면 Worker Pod 이름이 다음처럼 생성됩니다.
# dag_id가 replication_database_table_one 이고
# task_id가 db_replicaion_task 인 경우
replicationdatabasetableonedbreplicaiontask-hashvalue
Pod 이름이 읽기 어렵습니다. (Pod 이름이 생성되는 코드는 Airflow Github 코드에서 이 부분과 이 부분을 보면 알 수 있습니다.)
Pod 이름을 {dag_id}.{task_id}-hashvalue 같은 형태로 바꾸어 더 보기 쉽게 만들고 싶었습니다. 예를 들면 다음과 같습니다.
replication-database-table-one.db-replicaion-task-hashvalue
이를 위해 Airflow 코드에서 Pod 이름을 생성하는 로직 일부를 다음과 같이 수정했습니다. (주석 처리한 부분이 수정한 기존 코드입니다.)
# airflow/executors/kubernetes_executor.py
@staticmethod
def _create_pod_id(dag_id, task_id):
safe_dag_id = AirflowKubernetesScheduler._strip_unsafe_kubernetes_special_chars(dag_id)
safe_task_id = AirflowKubernetesScheduler._strip_unsafe_kubernetes_special_chars(task_id)
# return safe_dag_id + safe_task_id
return safe_dag_id + "." + safe_task_id
def _strip_unsafe_kubernetes_special_chars(string):
...
# return "".join(ch.lower() if ch.isalnum() else ch for ind, ch in enumerate(string))
return string.lower().replace("_", "-")
2) Operator WeightRule 변경
Airflow 오퍼레이터의 기본 weight_rule 은 WeightRule.DOWNSTREAM 입니다.
이 때문에 DAG 내에서 뒤쪽에 실행되는 Task들은 낮은 실행 우선순위를 갖게되고, DAG이 늘어날수록 전반적인 DAG 실행시간이 길어지는 경향이 있습니다. (이와 관련한 자세한 내용은 Line engineering 블로그 글에서 확인하실 수 있습니다.)
Task가 어느 위치에 있어도 같은 우선순위를 주기 위해 weight_rule 의 기본 값을 WeightRule.ABSOLUTE 로 수정했습니다.
# airflow/models/baseoperator.py
class BaseOperator:
def __init__(
...
# weight_rule=WeightRule.DOWNSTREAM, # type: str
weight_rule=WeightRule.ABSOLUTE, # type: str
...
)
3) Scheduler, Webserver 성능 관련 Configuration 값 수정
DAG 수가 늘어나면서 Scheduler가 전체 DAG을 파싱하는 속도가 점점 느려지는 문제가 있습니다. 따라서 Scheduler의 성능을 올려주어야 하는데, CPU 리소스를 더 늘리는 방법 말고도 Airflow Configuration 값을 다음과 같이 수정해서 성능을 향상시킬 수 있습니다.
AIRFLOW__SCHEDULER__PARSING_PROCESSES: 8 # 기본 값은 2입니다.
물론 parsing_process의 수를 늘리는 것에 비례해서 CPU 리소스는 더 잡아먹습니다. (따라서 Kubernetes에서 컨테이너 리소스도 더 늘려줘야 합니다.) 하지만 이런 트레이드오프가 있음에도 불구하고, DAG 실행 속도를 늘리는게 더 좋다고 판단했습니다.
또한 Webserver 접속 시 페이지 로드 지연을 줄이기 위해 다음 Configration 값들도 수정했습니다.
AIRFLOW__WEBSERVER__PAGE_SIZE: 50 # 기본 값은 100입니다.
AIRFLOW__WEBSERVER__WORKER_REFRESH_INTERVAL: 1800 # 기본 값은 30입니다.
AIRFLOW__WEBSERVER__WEB_SERVER_WORKER_TIMEOUT: 300 # 기본 값은 120입니다.
4) 빌드 과정에 라이브러리 추가
Airflow에서 제공하지않는 라이브러리를 사용하는 경우, 수동으로 라이브러리를 설치해야 합니다. 예를 들면 beautifulsoup4가 라이브러리를 예로 들 수 있습니다.
문제는 Webserver, Scheduler, Worker 모든 Pod에 설치해야 하는데, 매번 필요할 때마다 설치하는게 번거롭습니다. 이렇게 자주 사용할 라이브러리는 Airflow 프로젝트 소스 내에 extra-requirements.txt를 만들어 이 안에 명시하고 Airflow 이미지를 빌드할 때 이 extra-requirements.txt를 설치하도록 Dockerfile에 추가했습니다.
# extra-requirements.txt
beautifulsoup4==4.9.3
lxml==4.6.2
# Dockerfile
...
COPY ./extra-requirements.txt /extra-requirements.txt
RUN pip install -r extra-requirements.txt
...
성숙기를 향하여
Airflow를 Kubernetes로 옮기며, 그 환경에 알맞게 사용하는 큰 흐름은 마무리지었습니다. 그러나 아직 운영이 성숙해지기 위한 몇 가지 작업들이 남아있습니다.
Airflow 2.x으로 업그레이드
2020년 말 Airflow 2.0.0이 발표되었습니다. 메이저 버전이 바뀐만큼 기존에 있던 기능이 수정되기도 하고, 새로운 기능이 추가되기도 했습니다. 그 중 특히 눈에 띄는 것은 Scheduler의 로직의 퍼포먼스 향상과 HA(High Availity) 지원입니다.
앞으로 더 늘어날 DAG을 고려하면 2.x 버전으로 버전을 올리는게 매우 좋을 것으로 예상됩니다. 다만 아직은 Kubernetes에 Airflow를 운영한 초창기고 기존의 Airflow에 저장되어 있는 DAG들을 하나씩 리팩토링하며 옮기고 있기 때문에, 당장 버전을 올리지는 않을 계획입니다.
기존 DAG을 옮기는 작업을 마치고, 운영에 노하우가 좀 더 생기면 Airflow 버전을 올리는 작업을 진행할 예정입니다. 만약 Airflow의 공식 Helm Chart가 공개되면 개발 환경에서 테스트한 뒤 도입할 계획입니다.
이 글을 올리는 시점에 Airflow 2.1.0 버전으로 업그레이드 PoC 하고 있습니다. 성공적으로 배포 및 운영 후 관련 글을 작성해보도록 하겠습니다.
Grafana 대시보드 고도화
현재 Grafana 대시보드는 Pod의 CPU, Memory 리소스 정도만 보여주고 있습니다.
앞으로는 DAG 별 평균 처리 시간, 평균 지연 시간, 리소스 사용량 등을 대시보드에서 모니터링할 수 있도록 고도화할 예정입니다. 당장은 문제가 없도록 리소스를 넉넉히 설정했지만, 모니터링 후에 리소스 최적량을 찾아 리소스 다이어트도 해야합니다. 결과적으로 성장하는 조직에 문제가 없도록 Kubernetes 클러스터와 Airflow 운영에 대해 계속해서 고민하고, 하나씩 구현하는 것이 다음의 목표입니다.
Cluster 보안 작업
아직까지는 Kubernetes를 폭넓게 사용하고 있지는 않지만, 추후 Airflow를 비롯한 다른 서비스들을 GKE 클러스터에 배포할 예정입니다. 데이터 엔지니어링 팀은 앞으로 이 클러스터의 운영자로서 기본적인 보안 정책들을 잘 설정하고 관리할 책임을 느끼고 있습니다. Kubernetes RBAC 관리와 Security Policy, Secret 관리 등 보안적으로 이슈가 될만한 부분들을 점진적으로 개선할 준비를 하고 있습니다.
마무리하며
이상 쏘카 데이터 그룹에서 Airflow를 구축했던 과정에 대한 글을 마무리하려고 합니다. 약 3년간 Airflow를 다양한 방식으로 운영하며, 점진적으로 개선한 이야기를 들려드렸습니다.
정리하면 다음과 같습니다.
-
데이터 엔지니어링 팀이 없거나, 인원이 적은 경우엔 Managed Airflow인 Cloud Composer 또는 MWAA을 사용해 시간을 아끼는 방법
-
Airflow 환경을 구축할 인원이 있는 경우 Compute Engine, EC2와 Docker Compose를 사용해 운영
-
Jupyter Notebook을 사용해 Airflow DAG 파일을 관리하는 방법
-
사용이 쉽지만 관리가 어려운 트레이드오프가 확실히 존재
-
-
Kubernetes를 운영하며 위에서 발생하는 문제를 하나씩 해결하는 방법
- DAG Branch 별 Airflow 배포
- CI/CD
- 리소스 모니터링
-
Airflow DAG을 더 잘 작성할 수 있는 가이드 마련
- CLI 도구, 코드 리뷰, 포매터 설정 등
저희가 만든 방법이 항상 진리는 아니고, 서비스의 성장 시기와 조직의 인원 수에 따라 적절한 판단을 하는 것이 중요하다고 생각합니다. Airflow를 운영하려는 분들에게 저희의 경험이 도움이 되면 좋겠습니다. 혹시 데이터 엔지니어링팀이 하는 일이 궁금하시면 쏘카 데이터 그룹 - 데이터 엔지니어링 팀이 하는 일 글을 참고해주세요 😊
그동안 데이터 그룹에서 Airflow 환경을 구축하며 운영에 지속해서 노력하신 토마스, 제프, 플래시, 녹스, 하디, 험프리, 우민, 카일 모두 감사합니다. 또한 Airflow 관련 참고 자료들을 만들어주신 분들에게도 감사의 말씀을 전합니다.